Welcome to ned Productions (non-commercial personal website, for commercial company see ned Productions Limited). Please choose an item you are interested in on the left hand side, or continue down for Niall’s virtual diary.
Niall’s virtual diary:
Started all the way back in 1998 when there was no word ‘blog’ yet, hence ‘virtual diary’.
Original content has undergone multiple conversions Microsoft FrontPage => Microsoft Expression Web, legacy HTML tag soup => XHTML, XHTML => Markdown, and with a ‘various codepages’ => UTF-8 conversion for good measure. Some content, especially the older stuff, may not have entirely survived intact, especially in terms of broken links or images.
- A biography of me is here if you want to get a quick overview of who I am
- An archive of prior virtual diary entries are available here
- For a deep, meaningful moment, watch this dialogue (needs a video player), or for something which plays with your perception, check out this picture. Try moving your eyes around - are those circles rotating???
Latest entries: 
Word count: 2666. Estimated reading time: 13 minutes.
- Summary:
- The as built survey is documented. A boundary wall was painted, and a water intrusion issue in the pool cavity was encountered during testing. Furthermore, reference levels were remounted, and the as-built survey data was compiled following the completion of groundworks.
Thursday 23 July 2026: 20:29.
- Summary:
- The as built survey is documented. A boundary wall was painted, and a water intrusion issue in the pool cavity was encountered during testing. Furthermore, reference levels were remounted, and the as-built survey data was compiled following the completion of groundworks.


That ended up being four coats of cheap stain and one coat of expensive stain: we probably should have applied a fifth coat of cheap stain to reduce the blotchiness by a bit more, but we were out of time as camps began the next day so I just had to draw a line under it. It is my no means bad, just not as evenly coloured as I would personally prefer. Clara and Henry did well, it was their first time painting anything big and given the hot weather, staying the course required will power. My son, aged nine, clearly was very done with painting by the end of the fifth day of it, but then he is aged nine. Both did good quality work, I only had minor touch ups to do and those were principally due to their lack of experience painting a wall. Total all in cost including paying them €150 between them was €300 inc VAT for twenty-four metres of wall, or €6.25 per sqm. That’s very good in my opinion for painting an unpainted wall which tends to soak up the paint first time.
The pool cavity becomes a pool!
An unpleasant surprise turned up part way through the left wall staining: the pool cavity became a pool! Here it is with the water already mostly pumped out:

The water I reckon was about 400 mm deep if you include the stone layer at the bottom, and about 330 mm deep from the top of stone within that pool cavity. Very obviously, the tree cavity – which is much deeper – was dry as a bone, and it has not rained to any extent in weeks. So it is a mystery how it filled up like that!
I took the opportunity to use the water to test my percolation test hole. While we were digging out the pool cavity, we found at the bottom some possibly wet soil whereas the tree cavity was dry as a bone all the way down. That got me curious, so I had the groundworks guys dig me as deep a hole as the digger would go right next to the pool cavity where the future soakaway was planned to get installed:

That’s about 1.6 metres deep, and you can see a little bit of ground water down there, so obviously the water table is somewhat high around here. My concern was that installing a soakaway two metres down would be pointless if it was below the water table in summer, and I can confirm that that little bit of water didn’t budge in the days after it was dug. When the pool cavity filled up, it still didn’t budge after several days, so I wondered what if I filled that percolation test hole and emptied the pool cavity. Here is the result after five days:

It may have dropped by an inch in five days during ~28 C constant sunshine weather, so I’m going to claim that the height loss was entirely evaporation. The pool cavity remained bone dry after it was pumped out, and as the top of water in the percolation hole is about half a metre above the bottom of the pool cavity, so clearly my subsoil has almost zero percolation. This was another unpleasant surprise, as I had specifically chosen this site expecting subsurface static water pressure to cause flow over my subsoil heat exchanger into the ditch just behind my property, making the heat exchanger more efficient. Apparently I have here the exact opposite 🙁.
My current working theory is that my neighbour may have doused his garden with water to keep it alive, and due to the lack of percolation all that water promptly poured through his upper layer of topsoil over his subsoil into the pool cavity. If this is the case – I shall be watching things carefully – then there is a danger that the RC box going into the pool cavity could float if enough water surrounds it. To calculate that:
Pool cavity including EPS: 5885 x 3730.
EPS thickness: 200, with density 40 kg/m3.
RC thickness: 200 at bottom 215 at sides, with density 2,500 kg/m3.
Empty middle: 5055 x 2900, with density 1.25 kg/m3 (air).
So:
- Total horizontal area = 21.95 m2.
- Horizontal area of RC box = 18.27 m2.
- Horizontal area of empty air within RC box = 14.66 m2.
- Horizontal area of RC box = 18.27 m2.
- Bottommost 200 mm of EPS = 4.39 m3 => 175.60 kg.
- Nextmost 200 mm of RC box = 3.65 m3 => 9,133 kg plus 30 kg for the outer EPS => 9,163 kg.
- Remaining H metres of RC box = H x (40 x (21.95 - 18.27) + 2500 x (18.27 - 14.66) + 1.25 x 14.66)
- H x (40 x 0.736 + 2500 x 3.61 + 1.25 x 14.66)
- H x (29.44 + 9025 + 18.33)
- => H x 9073 kg.
Therefore:
H x 2195 (water) = -(9339 + (H - 0.4) x 9073) (RC tank)
H = ~0.51 metres above the base of the RC box
As the pool cavity is 0.77 metres below the top of T2 stone, and the T2 stone is about 200-250 mm deep, any water entering the pool cavity should overflow under the rest of the house before the RC tank would float, so we’re safe.
That said: you better believe I’ll be running the land drain out of the pool cavity no higher than 0.5 metres from its bottom, just in case.
Remounted the reference levels
Many years ago now, I had screwed three pieces of wood to the wooden fence to mark 75.08 over sea level, and all works since have used that as the reference level. Unfortunately, one bit of wood split and so had to be removed, and another got put out of alignment due to the wood staining. That left me with just one reference level marker, which got me anxious due to the lack of redundancy, so before the professional surveyor arrived I remounted two additional reference levels matching the one remaining one.
As my laser level is an indoor only model, I had to wait to dusk to be able to see the laser:


I remember being very, very tired when doing this work as I had been up at 4am and having to stay up until dusk really sucked. But I knew I’d get a lie in the following day, and I think I ended up asleep that following day until about 1pm as I had built up such a sleep debt.
When the surveyor came, we found that the bottom of those reference markers is more like 75.07 rather than 75.08. Thankfully, it didn’t seem to affect the stone levels according to the same survey, they were all spot on or slightly lower. I was also rather glad to learn that my marker on the wall other side of the site was just 4 mm off: my laser level, a Bosch prosumer model, promised <= 0.02% height error per metre of distance – over 35 metres, you would expect the error to therefore be less than 7 mm, so it was well within claimed specifications and only 43% worse than a commercial laser level.
The as-built survey
My surveyor, knowing that I have been more than a year without income, very kindly offered to reduce his bill if I did the post-processing work of taking his raw data and adjusting it to calculate the locations of all the popups. To explain, the problem with a pipe sticking up is you can’t directly measure the X-Y location of its centre, rather you can measure its side and then you need to offset that X-Y location in to the centre of the popup by half its diameter plus 15 mm (which is half the width of the X-Y location measuring stick). My surveyor would normally do that work and charge me for his time, but he reckoned me technically able enough to do it myself. And I am most grateful to him for that, every euro saved counts right now. Here is my as-built image of the site overlaid on the most recent drone photo taken a few days ago:
The levels shown above for the pool cavity, tree cavity and steel pad cavity are all as built; each popup as built is shown as a small green dot with its deviation from plans in text next to it; and the foulwater (FW) and stormwater (SA) all show the bottom of each pipe or inspection chamber as built. As with the sewer levels being somewhat off in places by up to 80 mm, so were the X-Y popup locations where the deviation was between 20 and 70 mm apart from the ESB ducts which are 100 mm off. Those ESB ducts being so far off is annoying, but as they are ESB ducts you can give them repeated kicks to get them back into position without disturbing the falls below in ways which matter (i.e. you can’t kick sewer pipes into position, you might create a trap) and/or you can bend them back into position as they go through the concrete slab.
So I think we’re all good, the only place where an out of place popup will matter is the one for the washing machine where it now pops up within the wall. We’ll have to perforate the wall, but as it’ll be behind the washing machine and you can’t see it I don’t think I care.
What’s next?
Here is the site right now. It’s only taken more than five years and €440,000 of my money to reach this:

Utter madness really. If I could go back to when I started this knowing what I know now, I would not have started building this house. It isn’t worth the years of time nor the hundreds of thousands of money I could have spent elsewhere.
Still, we are committed now, walking away would consign to the dustbin most of the money spent, so we can only go forwards.
Unfortunately, the remainder of the summer won’t be much fun for anybody:
- Next week the kids will most likely be painting the rightmost concrete block wall white. I’ll give them break days in between to decompress, but I expect it’ll take the week to complete.
- The week after that, the first week of August, has a bank holiday and I might take them somewhere nice. Megan has been studying all day long every day these past two weeks and shall be for the next two weeks, so I just need to take the kids away elsewhere. We do also have some furniture to upcycle, it just needs to be sanded and painted, it shouldn’t take long and most of the structural reworking has already been done.
- The second week of August is Megan’s final chartered accountancy exams week, that will surely be a stressful week for all.
- The third week of August is a WG14 C standards meeting, at which I’ll be presenting three of my papers. I’m sure Megan will take the kids to fun places as she’ll likely want to go have some fun herself after all these years of study.
- The fourth week of August I believe the kids return to school at the end of it, so the summer will be over for them.
You can see in the photo above that the soil spill pile hasn’t been removed! We’re waiting in Green Valley’s queue to have that removed. As with the groundworks, we won’t know when they’re going to remove it until the day before, so until then we’ll be unable to book anything much in advance lest it get wasted. So I expect e-bike rides, maybe day trips to things nearby which don’t cost much e.g. beaches, West Cork, that sort of thing.
What will come after August? That’s a very good question. I have taxes to sort out, we’re in a novel situation I haven’t dealt with before with those, so they’ll need to be figured out and that’ll likely take a few weeks and a few grand of fees to advisors. We are currently likely to run very low on cash some time this Autumn according to current projections, so I’ll need to do something to get ahead of that before it becomes critical.
Much I guess depends on when this AI investment bubble bursts. I was reading this week that at least 1.6 trillion dollars of AI datacentre building debt has been accumulated into off balance sheet Special Purpose Vehicles (SPVs), which is the same mechanism Enron used to blow itself up in the early 2000s. Apparently about half the borrowing comes from pension funds, a quarter from wealthy individuals, and the remainder is circularity of cross investment by SPV owners and government subsidies. When the party stops – and it will – contagion will set off a chain reaction of SPV collapse and at least one tech multinational will likely see a run on its stock, which means it’ll need to be bailed out by the taxpayer or bought at firesale prices by a competitor. So just like the bank bailouts and collapses of the 2009 financial collapse, but this time with tech multinationals. This fun game of musical chairs guarantees some will cease to exist, and the theory is that that whoever remains will thereafter profit handsomely.
I’m not personally sure that’s the case at all as I think those who build out the infrastructure won’t have the moat to reap more than a tiny slice of the profits from it – we saw something very similar with the telecommunications bubble up to the 2001 tech bubble collapse where most of the benefits and value accrued to those who used the telecommunications infrastructure, and very little to those who had built it out. If true, places like Europe which have mostly ignored the building out part of AI will benefit handsomely having skipped paying for its development, and getting to deploy upon it with all gusto as their powder will be still dry. Maybe there’s a diary entry in there explaining my thoughts on that, maybe I’ll write that in the Autumn if I run out of other things to do. We’ll see.
If time presents, I really do need to get back onto open source library development as I need to refresh my portfolio so I look more employable after the AI investment bubble bursts. It would do no harm for me to present at a few conferences either – I did submit to ACCU this year, but my talk was rejected. I’ll try again for 2027. Hopefully, though, I’ll have a house on my site soon and I can go work in that each and every day until we can move into it.
Word count: 6185. Estimated reading time: 30 minutes.
- Summary:
- The installation of the third round of groundworks is documented. Extended hours were spent on site, during which a significant underground cave was encountered and bridged. All foulwater pipes and inspection chambers were installed, pressure tested, and levels were accurately recorded. The project’s substantial costs are also detailed herein.
Friday 3 July 2026: 21:28.
- Summary:
- The installation of the third round of groundworks is documented. Extended hours were spent on site, during which a significant underground cave was encountered and bridged. All foulwater pipes and inspection chambers were installed, pressure tested, and levels were accurately recorded. The project’s substantial costs are also detailed herein.
Most of each day I press on with chores around the site or on this laptop (e.g. writing this very post, which I began writing about two weeks ago!), though this past week I’ve had the kids onsite as their school has ended for the summer which has severely reduced my productivity. Several times a day I get called upon to take decisions, do layout or interpret engineer or architect drawings. Most of the decisions are easy, they just need to be explained so everybody is on the same page, but some are genuinely hard with no obvious answer. I, as the eventual home owner, the buck stops with me so you take your best guess and we plough on.
In case you’re wondering if the engineer or architect should take those decisions instead, the problem is they won’t be able to answer for hours to days, during which no works would continue. That’s not feasible, so to keep things progressing you take your best guess, email your decisions to the architect and engineer, and if they dislike your choice enough hopefully they’ll let you know while it can still be fixed.
All this, plus the seventeen to eighteen hour days, is unsurprisingly very draining, though thankfully it’s been only for a maximum of four days per week so I’ve been able to recuperate in between these bouts of stress. This is the price of self building something atypical – the groundworks guys have been doing groundworks for over forty years, but they’ve never done ones like this before. They tell me they’ve greatly enjoyed themselves, rinse and repeat standard stuff is boring, and this job was definitely not boring, though they did find the pace frustratingly slow at times due to all the measuring and exactness. All this detail has also cost me dearly financially speaking, and I’ll tell you the total cumulative cost of all groundworks done towards the end of this diary entry.
Table of Contents
The Plan
Before recounting the story of these popups installation, the previous two rounds of groundworks were as follows:
September 2022: Installation of services: mains electricity, mains telecoms, mains water and mains foulwater along with small gravelled section for shipping container secure storage and site office.
April 2024: Installation of subsoil heat exchanger, removal of lots of soil, addition of dozens of tonnes of T2 structural gravel and permeable membrane. Due to all the soil removal and very expensive gravel added, this was an expensive round – though these past three weeks will probably cost about the same.
The original plan for this third round of groundworks (popups installation) was:

Total works this round:
- Nine foulwater popups.
- Seven inspection chambers.
- Four ESB ducts.
- Three stormwater popups.
- Three cavities.
- Two radon sumps.
- One mains water.
- Hundreds of meters of pipe/duct to connect between everything.
And this is it finished:

The Roof
The lads very kindly let me add the roof to their materials order and I went and visited all the building suppliers to get quotes to drive the price down to minimum, which was only possible thanks to it being a large order. Here are the three thousand or so tiles for the roof, with the fascia and soffit actually being behind the tiles next to the wall, but you can’t see that in this photo:

I reckon I saved myself about one third of the materials cost by doing this. Labour is by far the biggest cost in a build, so the effect on the overall cost is much less than one third, but it’s still a very nice saving. Unfortunately we ended up with a lot of hassle from this as the building supplier chosen was the cheapest for a reason – wrong items were supplied, items were missing, one of their trucks got stuck and I had to go find a local tractor to pull it out, the list went on in terms of inconvenience, hassle and stress.
But I did save hundreds of euro, so I guess my time and lack of sleep was worth it.
The Cave
Last round of groundworks we unfortunately hadn’t taken the depth of where the mains services enter the property, and therefore we couldn’t calculate the falls for any of the popups. So the very first item to do was to dig a hole at the front where the services enter, and get a measuring tape on them.
I was actually standing in that hole holding the mains water pipe out of the way of the digger’s arm when everybody panicked and told me to get out of the hole ASAP. It turns out I was quite literally standing over an underground cave, and the digger had just exposed an entrance exactly below where I had been standing:


The top of this underground cavity was about two metres down. It turned out to be four metres long, two meters wide, and about one metre high. It is almost exactly beneath the public footpath outside my driveway, and this is how it looks inside:
As much as it was surprising that we hadn’t discovered this during the last round of groundworks (we probably didn’t dig deep enough, and just missed it), underground cavities are known around this area: an underground river passes deep beneath this locality, and as it carries material away it undermines everything above it over time. We know that this footpath was built around twenty years ago, therefore around one metre of material is removed every twenty years. That meant that my driveway was likely to collapse before I would be dead, which meant I was going to have to spend a bunch of money I hadn’t intended. The solution was a reinforced concrete slab to bridge between the good bits of land so as the underground cave continues to deepen over time, my driveway should get held up until I’m dead (the public footpath and public driveway outside my property are my local government’s problem, not mine). Here you can see we backfilled part of the cave at the right, enough to pour concrete on top, then double layered steel mesh to form the slab:

We then filled the whole base with three cubic metres of concrete, which is oddly satisfying to watch getting poured:
We then dropped onto the reinforced concrete slab a heavy duty reinforced concrete manhole riser of the type they use for high traffic roads: this should stabilise the driveway above by taking weight from above and landing it evenly onto the concrete slab, so rather than weight pushing sideways it should push downwards:



Once that excitement was over, we now could calculate the levels for all the popups: anything taking a toilet flush was to have 1:80 fall, anything not taking a toilet flush was to have 1:40 fall. We’ll get back to that later, but here are both sewer lines being tested by my children pouring water into the inspection chambers and I in the big sewer making sure that the water flows:
Before anyone emails to mention that one side is unfinished and that will be a problem down the line, that side hasn’t been pointed yet. I may do that work myself as I need to mix a batch of cement anyway to patch up holes in the western wall before we paint it.
Land drains and cavities
We installed three land drains around the bottom of the edge of the T2 stone layer: one around the top of the tree cavity, one at the far left as once the house is up you won’t get a digger down there, and one around the bottom of the pool cavity:


Land drains are mainly there to prevent the build up of water which if it turned to ice, it would cause the T2 stone layer to expand, pushing up the house above. By digging a small ditch around the T2 stone layer, any water which gets into the T2 stone layer should flow into the ditch, and then the land drain spreads that around so it drains away. Similarly, if water tries to enter the T2 stone layer from outside horizontally, it will fall downwards and hit the land drain rather than enter the T2 stone layer. All this is great, however the land drain pipe is full of holes and not strong – it crushes easily. So you only ever install it last-most possible, which is exactly what we’ve done leaving the coils above ground for continuing installation later.
We dug out three cavities: the pool cavity, the pad cavity, and the tree cavity:

These are the pool and tree cavities: the pool cavity is the largest, but the tree cavity is the deepest:


The pad cavity is just 100 mm deep, but we had to spend enormous care here as most of the house services route around it, and we cannot disturb the subsoil underneath this as this pad takes the most weight of any pad in the house. So much weight in fact we need to triple mesh the concrete pad above it, and two large steel poles bear down onto this pad from above:

The sewer to the left is the master bedroom ensuite toilet, and the sewer to the right is the master bedroom ensuite shower plus upstairs bathroom. Right in between these two where the pad will go there will be his and hers sinks. When I’ll be brushing my teeth to go to bed, the most intense weight from above my head shall be load spread under my feet. Which is food for thought!
In case you are wondering why this pad takes the most weight anywhere in the house, it is because the rainwater harvesting tanks are above. When full, these add twenty metric tonnes to the rest of the weight above which includes the outer block leaf upstairs – those sit on metal girders which then puts as much load onto the ground floor outer block leaf as possible, but for the single corner where there is no other support that’s what the two steel poles and this pad support.
Popup installation over time
After each work day I had the drone take an aerial photo from thirty, forty and fifty metres up. I tried to find free of cost software to turn the thirty metre height photos into a timelapse video, but I couldn’t find any, so I had Step 3.7 Flash write a utility program which takes in photos, analyses them, chooses the best reference photo, and then scales-rotates-crops all the others to match. It also adjusts brightness so everything is roughly the same brightness over time, then emits a video in your choice of AV1, h.265 or h.264. Step 3.7 took about two hours to complete this task for a total cost of about US$0.66, and I only had to re-steer it once. The results are acceptable:
Here is the code it wrote: not bad methinks, I probably wouldn’t have done much better myself and furthermore I was and am not familiar with OpenCV for image analysis and processing, whereas it knew what it was doing relative to me:
#!/usr/bin/env python3
"""make_timelapse.py — Aligned AV1/H.264/H.265 timelapse from DJI aerial JPEGs."""
from __future__ import annotations
import argparse
import math
import os
import subprocess
import sys
from concurrent.futures import ThreadPoolExecutor
from typing import NamedTuple
import cv2
import numpy as np
# ── Linearization (sRGB inverse EOTF) ─────────────────────────────────────
def srgb_to_linear(val: np.ndarray) -> np.ndarray:
val = val.astype(np.float32) / 255.0
lo = val <= 0.04045
hi = ~lo
out = np.empty_like(val, dtype=np.float32)
out[lo] = val[lo] / 12.92
out[hi] = ((val[hi] + 0.055) / 1.055) ** 2.4
return out
def linear_to_srgb(val: np.ndarray) -> np.ndarray:
lo = val <= 0.0031308
hi = ~lo
out = np.empty_like(val, dtype=np.float32)
out[lo] = 12.92 * val[lo]
out[hi] = 1.055 * (val[hi] ** (1.0 / 2.4)) - 0.055
return np.clip(out * 255.0, 0, 255).astype(np.uint8)
# ── Data structures ────────────────────────────────────────────────────────
class FrameResult(NamedTuple):
filename: str
index: int # 0-based source index
M: np.ndarray | None # 2x3 similarity matrix (src→ref), None if skipped
inliers: int # RANSAC inlier count
total_matches: int
skipped: bool
skip_reason: str
warp_bgr: np.ndarray | None # uint8 BGR after warp
valid_rect: tuple[int, int, int, int] | None # (x0, y0, x1, y1) in ref space
crop_rect: tuple[int, int, int, int] | None # same
class TimelapseState:
def __init__(self) -> None:
self.last_output_bgr: np.ndarray | None = None
# ── ORB matching (uint8 BGR grayscale) ─────────────────────────────────────
def match_to_reference(
ref_gray: np.ndarray,
curr_gray: np.ndarray,
fringe_mask: np.ndarray | None,
) -> tuple[np.ndarray | None, int, int]:
"""Return (M, inliers, total_good_matches). M=None if insufficient matches."""
orb = cv2.ORB_create(nfeatures=2000, fastThreshold=5)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=False)
kp_ref, des_ref = orb.detectAndCompute(ref_gray, None)
kp_curr, des_curr = orb.detectAndCompute(curr_gray, None)
if des_ref is None or des_curr is None or len(kp_ref) < 4 or len(kp_curr) < 4:
return None, 0, 0
raw_matches = bf.knnMatch(des_ref, des_curr, k=2)
good = []
for pair in raw_matches:
if len(pair) == 2:
m, n = pair
if m.distance < 0.75 * n.distance:
good.append(m)
if len(good) < 4:
return None, len(good), len(good)
src_pts = np.float32([kp_curr[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp_ref[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
if fringe_mask is not None:
h, w = curr_gray.shape
y0, y1 = int(0.30 * h), int(0.70 * h)
x0, x1 = int(0.30 * w), int(0.70 * w)
def in_fringe(pts: np.ndarray) -> np.ndarray:
x = pts[:, 0, 0]
y = pts[:, 0, 1]
return ~((y0 <= y) & (y < y1) & (x0 <= x) & (x < x1))
fringe_src = in_fringe(src_pts)
fringe_dst = in_fringe(dst_pts)
keep = fringe_src & fringe_dst
src_pts = src_pts[keep]
dst_pts = dst_pts[keep]
if src_pts.shape[0] < 4:
return None, 0, len(good)
M, inlier_mask = cv2.estimateAffinePartial2D(
src_pts,
dst_pts,
method=cv2.RANSAC,
ransacReprojThreshold=1.0,
maxIters=2000,
confidence=0.99,
refineIters=10,
)
if M is None:
return None, src_pts.shape[0], len(good)
inliers = int(inlier_mask.sum()) if inlier_mask is not None else src_pts.shape[0]
return M, inliers, len(good)
def build_fringe_mask(h: int, w: int) -> np.ndarray | None:
y0, y1 = int(0.30 * h), int(0.70 * h)
x0, x1 = int(0.30 * w), int(0.70 * w)
edge_pixels = (
y0 * w
+ (h - y1) * w
+ y1 * x0
+ y1 * (w - x1)
)
if edge_pixels < 4000:
return None
mask = np.zeros((h, w), dtype=np.uint8)
mask[:y0, :] = 255
mask[y1:, :] = 255
mask[y0:y1, :x0] = 255
mask[y0:y1, x1:] = 255
return mask
# ── Transform validation ────────────────────────────────────────────────────
def decompose_similarity(M: np.ndarray) -> tuple[float, float, float, float]:
tx = float(M[0, 2])
ty = float(M[1, 2])
s = float(np.sqrt(M[0, 0] ** 2 + M[1, 0] ** 2))
theta = float(np.degrees(np.arctan2(M[1, 0], M[0, 0])))
return s, theta, tx, ty
def validate_transform(M: np.ndarray) -> str | None:
s, theta, _, _ = decompose_similarity(M)
if not (0.90 <= s <= 1.10):
return f"scale={s:.4f} outside [0.90, 1.10]"
if abs(theta) > 5.0:
return f"rotation={theta:.2f}deg outside ±5°"
return None
# ── Pass 0: pairwise scoring ────────────────────────────────────────────────
def score_pair(ref_gray: np.ndarray, curr_gray: np.ndarray, fringe_mask: np.ndarray | None) -> float:
M, inliers, total = match_to_reference(ref_gray, curr_gray, fringe_mask)
if M is None:
return float("inf")
cap_err = validate_transform(M)
if cap_err:
return float("inf")
if inliers < 4:
return float("inf")
return 1.0 / (inliers + 1)
def _score_row(
r: int,
n: int,
greys: list[np.ndarray | None],
fringe_masks: list[np.ndarray | None],
) -> float:
if greys[r] is None:
return float("inf")
total = 0.0
for j in range(n):
if j == r or greys[j] is None:
continue
total += score_pair(greys[r], greys[j], fringe_masks[j])
return total
def select_reference_frame(
files: list[str],
greys: list[np.ndarray | None],
fringe_masks: list[np.ndarray | None],
) -> int:
print("Pass 0: pairwise scoring to select reference frame...", file=sys.stderr)
n = len(files)
total_scores: list[float] = [0.0] * n
workers = min(os.cpu_count() or 1, n)
with ThreadPoolExecutor(max_workers=workers) as executor:
futures = {
executor.submit(_score_row, r, n, greys, fringe_masks): r
for r in range(n)
}
for future in futures:
r = futures[future]
total_scores[r] = future.result()
ref_idx = int(np.argmin(total_scores))
for i, sc in enumerate(total_scores):
print(f" {files[i]}: total_score={sc:.4f}", file=sys.stderr)
print(f"Selected reference frame: {files[ref_idx]} (index {ref_idx})", file=sys.stderr)
return ref_idx
# ── Valid-content rect via mask warp ───────────────────────────────────────
def valid_content_rect(M: np.ndarray, h_src: int, w_src: int, h_ref: int, w_ref: int) -> tuple[int, int, int, int]:
mask_src = np.ones((h_src, w_src), dtype=np.uint8) * 255
warped_mask = cv2.warpAffine(
mask_src, M, (w_ref, h_ref), borderMode=cv2.BORDER_CONSTANT, borderValue=0
)
ys, xs = np.where(warped_mask > 0)
if len(xs) == 0:
return (0, 0, 0, 0)
return int(xs.min()), int(ys.min()), int(xs.max() + 1), int(ys.max() + 1)
# ── Peripheral annulus mask ────────────────────────────────────────────────
def peripheral_mask(h: int, w: int) -> np.ndarray:
y_top = int(math.ceil(0.10 * h))
y_bot = int(math.floor(0.90 * h))
x_left = int(math.ceil(0.10 * w))
x_right = int(math.floor(0.90 * w))
mask = np.zeros((h, w), dtype=bool)
mask[:y_top, :] = True
mask[y_bot:, :] = True
mask[y_top:y_bot, :x_left] = True
mask[y_top:y_bot, x_right:] = True
return mask
# ── Brightness correction ──────────────────────────────────────────────────
def compute_gains(
ref_linear: np.ndarray, frame_linear: np.ndarray, peri_mask: np.ndarray
) -> np.ndarray:
gains = np.zeros(3, dtype=np.float32)
for c in range(3):
r = ref_linear[:, :, c][peri_mask].astype(np.float32)
f = frame_linear[:, :, c][peri_mask].astype(np.float32)
denom = (f ** 2).sum()
if denom < 1e-12:
gains[c] = 1.0
else:
gains[c] = (r * f).sum() / denom
return gains
def apply_gains(frame: np.ndarray, gains: np.ndarray) -> np.ndarray:
return frame * gains.astype(np.float32)
# ── Encoding ───────────────────────────────────────────────────────────────
AV1_ARGS = [
"-c:v", "libsvtav1",
"-crf", "18",
"-preset", "5",
"-pix_fmt", "yuv420p",
"-color_primaries", "bt709",
"-color_trc", "bt709",
"-colorspace", "bt709",
"-movflags", "+faststart",
]
H264_ARGS = [
"-c:v", "libx264",
"-crf", "15",
"-pix_fmt", "yuv420p",
"-color_primaries", "bt709",
"-color_trc", "bt709",
"-colorspace", "bt709",
]
H265_ARGS = [
"-c:v", "libx265",
"-crf", "16",
"-pix_fmt", "yuv420p",
"-color_primaries", "bt709",
"-color_trc", "bt709",
"-colorspace", "bt709",
]
CODEC_MAP = {"av1": AV1_ARGS, "h264": H264_ARGS, "h265": H265_ARGS}
def check_ffmpeg() -> None:
try:
subprocess.run(
["ffmpeg", "-version"],
capture_output=True,
check=True,
)
except (FileNotFoundError, subprocess.CalledProcessError):
print(
"ERROR: ffmpeg not found. Install with: brew install ffmpeg",
file=sys.stderr,
)
sys.exit(1)
def check_av1_encoder(requested_av1: bool) -> str | None:
try:
result = subprocess.run(
["ffmpeg", "-encoders"],
capture_output=True,
text=True,
check=True,
)
except (FileNotFoundError, subprocess.CalledProcessError):
return None
encoders = result.stdout.lower()
if "libsvtav1" in encoders:
return "libsvtav1"
if requested_av1:
print(
"WARNING: libsvtav1 not found in ffmpeg build. "
"Attempting libaom-av1 fallback (slower).",
file=sys.stderr,
)
if "libaom-av1" in encoders:
return "libaom-av1"
return None
def build_ffmpeg_args(
width: int, height: int, fps: int, output: str, encoder: str | None, codec: str
) -> list[str]:
if encoder is None:
print(
"ERROR: No suitable AV1 encoder found in ffmpeg. "
"Install with: brew install ffmpeg (includes libsvtav1).",
file=sys.stderr,
)
sys.exit(1)
args = [
"ffmpeg",
"-y",
"-f", "rawvideo",
"-pix_fmt", "bgr24",
"-s", f"{width}x{height}",
"-r", str(fps),
"-i", "-",
]
if codec == "av1":
if encoder == "libsvtav1":
args.extend(AV1_ARGS)
else:
args.extend(["-c:v", encoder, "-crf", "30", "-cpu-used", "4", "-pix_fmt", "yuv420p",
"-color_primaries", "bt709", "-color_trc", "bt709", "-colorspace", "bt709"])
else:
args.extend(CODEC_MAP[codec])
args.append(output)
return args
def run_encoder(
frames_iter, width: int, height: int, fps: int, output: str, encoder: str | None, codec: str
) -> bool:
args = build_ffmpeg_args(width, height, fps, output, encoder, codec)
proc = subprocess.Popen(
args,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE,
)
ok = True
try:
for bgr in frames_iter:
try:
proc.stdin.write(bgr.tobytes())
except BrokenPipeError:
stderr_text = proc.stderr.read().decode("utf-8", errors="replace")
print(f"ERROR: ffmpeg pipe broken. stderr:\n{stderr_text}", file=sys.stderr)
ok = False
break
finally:
if proc.stdin and not proc.stdin.closed:
proc.stdin.close()
stderr_text = b""
if proc.stderr:
stderr_text = proc.stderr.read()
ret = proc.wait()
if ret != 0:
print(
f"ERROR: ffmpeg exited with code {ret}.\n"
+ stderr_text.decode("utf-8", errors="replace"),
file=sys.stderr,
)
ok = False
return ok
# ── Main pipeline ─────────────────────────────────────────────────────────
def process_sequence(
input_dir: str,
output: str,
frames_per_image: int,
fps: int,
codec: str,
encoder_choice: str | None = None,
scale_factor: float | None = None,
) -> None:
check_ffmpeg()
requested_av1 = codec == "av1"
encoder = encoder_choice if encoder_choice else check_av1_encoder(requested_av1)
exts = {".jpg", ".jpeg", ".JPG", ".JPEG"}
files = sorted(
f for f in os.listdir(input_dir)
if os.path.splitext(f)[1] in exts
)
if not files:
print(f"ERROR: No JPEG files found in {input_dir}", file=sys.stderr)
sys.exit(1)
print(f"Found {len(files)} images.", file=sys.stderr)
# Load all frames (needed for Pass 0 pairwise scoring)
all_bgrs: list[np.ndarray | None] = []
all_grays: list[np.ndarray | None] = []
all_fringe: list[np.ndarray | None] = []
h_ref, w_ref = 0, 0
for fname in files:
path = os.path.join(input_dir, fname)
bgr = cv2.imread(path)
if bgr is None:
print(f"WARNING: Cannot load {fname}", file=sys.stderr)
all_bgrs.append(None)
all_grays.append(None)
all_fringe.append(None)
continue
h, w = bgr.shape[:2]
if h_ref == 0:
h_ref, w_ref = h, w
all_bgrs.append(bgr)
all_grays.append(cv2.cvtColor(bgr, cv2.COLOR_BGR2GRAY))
all_fringe.append(build_fringe_mask(h, w))
if h_ref == 0:
print("ERROR: Could not load any valid images.", file=sys.stderr)
sys.exit(1)
# ── Pass 0: select reference frame ─────────────────────────────────────
ref_idx = select_reference_frame(files, all_grays, all_fringe)
ref_bgr = all_bgrs[ref_idx]
ref_gray = all_grays[ref_idx]
assert ref_bgr is not None and ref_gray is not None
# ── Pass 1: compute transforms to chosen reference ──────────────────────
results: list[FrameResult] = []
valid_rects: list[tuple[int, int, int, int]] = []
for idx, fname in enumerate(files):
src_bgr = all_bgrs[idx]
curr_gray = all_grays[idx]
if idx == ref_idx:
full_rect = (0, 0, w_ref, h_ref)
results.append(
FrameResult(
filename=fname,
index=idx,
M=np.eye(2, 3, dtype=np.float32),
inliers=0,
total_matches=0,
skipped=False,
skip_reason="",
warp_bgr=ref_bgr,
valid_rect=full_rect,
crop_rect=None,
)
)
valid_rects.append(full_rect)
continue
if src_bgr is None or curr_gray is None:
msg = f"corrupt JPEG"
print(f"WARNING: Skipping {fname}: {msg}", file=sys.stderr)
results.append(
FrameResult(
filename=fname,
index=idx,
M=None,
inliers=0,
total_matches=0,
skipped=True,
skip_reason=msg,
warp_bgr=None,
valid_rect=None,
crop_rect=None,
)
)
valid_rects.append((0, 0, 0, 0))
continue
h_src, w_src = src_bgr.shape[:2]
# Try fringe mask then full frame against chosen reference
fringe_mask = build_fringe_mask(h_src, w_src)
use_fringe = fringe_mask is not None
M, inliers, total = match_to_reference(ref_gray, curr_gray, fringe_mask)
if M is None and use_fringe:
M, inliers, total = match_to_reference(ref_gray, curr_gray, None)
skipped = False
skip_reason = ""
if M is None:
skipped = True
skip_reason = f"too few matches (got {total} good, 0 inliers)"
print(
f"WARNING: Skipping {fname}: {skip_reason}",
file=sys.stderr,
)
else:
cap_err = validate_transform(M)
if cap_err:
skipped = True
skip_reason = f"transform cap exceeded: {cap_err}"
print(
f"WARNING: Skipping {fname}: {skip_reason}",
file=sys.stderr,
)
else:
if inliers < 6:
skipped = True
skip_reason = f"only {inliers} inliers (minimum 6 required)"
print(
f"WARNING: Skipping {fname}: {skip_reason}",
file=sys.stderr,
)
elif inliers < 15:
print(
f"WARNING: {fname}: low inlier count {inliers} "
"(model may be unreliable)",
file=sys.stderr,
)
# Warn (do not reject) on large absolute translation vs reference
if not skipped and M is not None:
_, _, tx, ty = decompose_similarity(M)
if abs(tx) > 500.0 or abs(ty) > 500.0:
print(
f"WARNING: Frame {idx} ({fname}): large translation "
f"({tx:.1f}, {ty:.1f})px from reference — verify alignment",
file=sys.stderr,
)
if skipped:
results.append(
FrameResult(
filename=fname,
index=idx,
M=None,
inliers=inliers,
total_matches=total,
skipped=True,
skip_reason=skip_reason,
warp_bgr=None,
valid_rect=None,
crop_rect=None,
)
)
valid_rects.append((0, 0, 0, 0))
continue
# Warp to reference space
warped = cv2.warpAffine(
src_bgr, M, (w_ref, h_ref), borderMode=cv2.BORDER_REPLICATE
)
vcr = valid_content_rect(M, h_src, w_src, h_ref, w_ref)
results.append(
FrameResult(
filename=fname,
index=idx,
M=M,
inliers=inliers,
total_matches=total,
skipped=False,
skip_reason="",
warp_bgr=warped,
valid_rect=vcr,
crop_rect=None,
)
)
valid_rects.append(vcr)
# ── Compute final crop rect ─────────────────────────────────────────────
x0 = max(r[0] for r in valid_rects)
y0 = max(r[1] for r in valid_rects)
x1 = min(r[2] for r in valid_rects)
y1 = min(r[3] for r in valid_rects)
crop_w = x1 - x0
crop_h = y1 - y0
pad_w = (2 - crop_w % 2) % 2
pad_h = (2 - crop_h % 2) % 2
x1 += pad_w
y1 += pad_h
crop_w += pad_w
crop_h += pad_h
if crop_w <= 0 or crop_h <= 0:
print(
f"ERROR: Crop dimensions are zero or negative ({crop_w}x{crop_h}). "
f"Valid-content rects: {valid_rects}",
file=sys.stderr,
)
sys.exit(1)
ref_area = w_ref * h_ref
crop_area = crop_w * crop_h
if crop_area < 0.5 * ref_area:
print(
f"ERROR: Crop area ({crop_area} px = {crop_area/ref_area*100:.1f}% of reference) "
f"is below 50% guard. Aborting.",
file=sys.stderr,
)
sys.exit(1)
print(
f"Crop rect: x={x0}..{x1}, y={y0}..{y1}, size={crop_w}x{crop_h} "
f"({crop_area/ref_area*100:.1f}% of reference)",
file=sys.stderr,
)
for i, res in enumerate(results):
if res.valid_rect is not None and not res.skipped:
x0f, y0f, x1f, y1f = res.valid_rect
cc = (
max(x0f, x0),
max(y0f, y0),
min(x1f, x1),
min(y1f, y1),
)
old = results[i]
results[i] = old._replace(crop_rect=cc)
# ── Pass 2: crop, brightness correct, generate output frames ─────────────
state = TimelapseState()
peri = peripheral_mask(crop_h, crop_w)
out_w = crop_w if scale_factor is None else max(2, int(round(crop_w * scale_factor / 2)) * 2)
out_h = crop_h if scale_factor is None else max(2, int(round(crop_h * scale_factor / 2)) * 2)
ref_crop_bgr = results[ref_idx].warp_bgr[y0:y1, x0:x1]
ref_linear = srgb_to_linear(ref_crop_bgr.astype(np.float32))
def gen_output_frames():
last_output = ref_crop_bgr
for res in results:
if res.skipped or res.warp_bgr is None:
if state.last_output_bgr is None:
last_output = ref_crop_bgr
state.last_output_bgr = ref_crop_bgr
out = (
state.last_output_bgr
if scale_factor is None
else cv2.resize(
state.last_output_bgr, (out_w, out_h), interpolation=cv2.INTER_AREA
)
)
for _ in range(frames_per_image):
yield out
print(
f"WARNING: Frame {res.index} ({res.filename}): {res.skip_reason}. "
f"Substituting previous frame.",
file=sys.stderr,
)
continue
crop_bgr = res.warp_bgr[y0:y1, x0:x1]
if res.index == ref_idx:
corrected_bgr = crop_bgr
else:
frame_linear = srgb_to_linear(crop_bgr.astype(np.float32))
gains = compute_gains(ref_linear, frame_linear, peri)
extreme = ((gains > 1.5) | (gains < 0.5)).any()
if extreme:
print(
f"WARNING: Frame {res.index} ({res.filename}): "
f"extreme gains {gains.tolist()} — check exposure",
file=sys.stderr,
)
corrected_linear = apply_gains(frame_linear, gains)
corrected_bgr = linear_to_srgb(corrected_linear)
clipped = np.count_nonzero(
(corrected_bgr == 0) | (corrected_bgr == 255)
)
total_px = corrected_bgr.size
if total_px > 0 and clipped > 0.01 * total_px:
pct = clipped / total_px * 100
print(
f"WARNING: Frame {res.index} ({res.filename}): "
f"{pct:.2f}% pixels clipped after correction",
file=sys.stderr,
)
state.last_output_bgr = corrected_bgr
last_output = corrected_bgr
out = (
corrected_bgr
if scale_factor is None
else cv2.resize(
corrected_bgr, (out_w, out_h), interpolation=cv2.INTER_AREA
)
)
for _ in range(frames_per_image):
yield out
ok = run_encoder(
gen_output_frames(),
width=out_w,
height=out_h,
fps=fps,
output=output,
encoder=encoder,
codec=codec,
)
if ok:
print(f"Done: {output} ({len(files)} sources × {frames_per_image} frames each)", file=sys.stderr)
else:
print(f"ERROR: Encoding failed. Output may be incomplete: {output}", file=sys.stderr)
sys.exit(1)
def main() -> None:
parser = argparse.ArgumentParser(
description="Generate an aligned AV1/H.264/H.265 timelapse from DJI aerial JPEGs."
)
parser.add_argument("--input", default="./input", help="Input JPEG directory")
parser.add_argument("--output", default="./timelapse.mp4", help="Output video path")
parser.add_argument(
"--frames-per-image",
type=int,
default=30,
help="Output frames per source image (default: 30)",
)
parser.add_argument(
"--codec",
choices=["av1", "h264", "h265"],
default="av1",
help="Output video codec (default: av1)",
)
parser.add_argument(
"--fps",
type=int,
default=30,
help="Output frame rate (default: 30)",
)
parser.add_argument(
"--scale-factor",
type=float,
default=None,
help="Output resolution as a fraction of input dimensions (default: no scaling)",
)
args = parser.parse_args()
scale_factor = args.scale_factor
if not os.path.isdir(args.input):
print(f"ERROR: Input directory does not exist: {args.input}", file=sys.stderr)
sys.exit(1)
process_sequence(
input_dir=args.input,
output=args.output,
frames_per_image=args.frames_per_image,
fps=args.fps,
codec=args.codec,
scale_factor=scale_factor,
)
if __name__ == "__main__":
main()
Pressure testing the subsoil heat exchanger
The lads accidentally snapped the subsoil heat exchanger pipe twice and ‘bruised’ it a third time. So we needed to do a pressure test to make sure that the repairs weren’t leaking:


We plugged the mains water in into the subsoil heat exchanger, let the 150 metres of it fill with water, then let it wash out all the crap that was in there, finally we attached a radiator pressure tester. What this does is pump water in until you reach a desired pressure. You then leave it sit for a few hours and check that the pressure doesn’t drop, which would indicate a leak. We tested it at 100 psi, which is about seven bar. This is a bit much, to be honest, but the groundworks lads still work in imperial so 100 psi felt right to them. As all our fittings were plastic, they were right to use a higher test pressure, but the pipe itself is only rated to twelve bar or so. I personally would have used five bar, I think that enough for plastic fittings test (also it’s less hand pumping to get there and you get less pipe stretching so it’s way faster). Still, glad to know it’s all good at seven bar.
As built
This is my as-built overlay with the current site picture overlaid by the portion of items which were done in round three of groundworks. I personally measured the bottom of each foulwater popup and inspection chamber using my own laser level, plus the levels of each of the T2 stone layers throughout the site. I measured by sticking my tape measure down each popup and then taking where the laser appeared on the tape measure – note that for any popup less than 110 mm, I added 50 mm to the depth for any popup above a 90 degree bend, as my tape measure probably intersected the side of the bend and therefore read the depth too high. I have placed the intended plan picture from above directly below this one, so you can compare them easily.
Comparing these two, the leftmost inspection chambers are lower than planned, though the second down leftmost IC is relatively less lower, and therefore the fall between the topmost left two is half that planned. At the resulting 1:80 fall, we may get some soap and food residue dropping out between those two inspection chambers. The falls within the house to the IC are as planned, 290 mm was planned and 300 mm was achieved. The main bathroom toilet has a fall less than 1:80 which is unfortunate, however as it’s a 90 degree turn it should have higher velocity and I think it’ll be okay – I might stick my inspection camera down there, and see if water is pooling. The leftmost sewer line has a fall of 1:46, steeper than the planned 1:80, and then to the main sewer manhole it is also 1:46, where it should be 1:80.
For the rightmost sewer, the topmost IC is considerably lower than planned: a full 320 mm. The shower sewer has a steep fall to the ensuite toilet sewer of 1:23, then there is an even steeper fall to the IC outside of 1:19. This is obviously far steeper than 1:80. I didn’t lift the cover of the bottom rightmost IC as it’s covered with gravel, but I can say that the total fall from the top rightmost IC to the main sewer manhole is 1:68.
For the upper stormwater, everything is more or less spot on apart from the IC which being so deep was hand made from concrete and a two foot diameter concrete pipe. It’s a few dozen millimetres deeper than it ought to be, but not too bad.
Finally, the drone photo reveals that three popups were installed slightly out of place: the washing machine one is to the top right of where it should be, the small right ESB duct is to the bottom left of where it should be, and the bottom middle ESB duct emerges to the bottom left of where it should be. Of those, the only one which matters is the washing machine one, it’s now within the wall, but I’m sure we can build around that okay.
The soil pile excavated and materials added
As always, one is amazed at how much soil you dig out every time. Digging it out of course ‘fluffs’ the soil, making it take up twice the volume it used to be when in the ground. Still, that’s a fair soil pile, we basically were out of storage space:

There is at least ten truck loads of soil to remove, generally it is twenty metric tonnes per truck, so that is two hundred metric tonnes and that will cost me at least three grand ex VAT thanks to EU rules around soil transport.
Deposited into the ground was two truck loads of pipe grit, which is forty metric tonnes. A further three truck loads of T2 stone were spread around, which is sixty metric tonnes which is approximately 30 m3. So two hundred tonnes was removed and replaced with one hundred tonnes of expensive stone, leaving a net one hundred tonnes removed which are the three cavities shown above, and pipes installed.
In 2024 T2 stone cost €505 ex VAT per truck load. It now costs €600 ex VAT per truck load. I didn’t get a price for the pipe grit, it’ll be a bit cheaper, but certainly a good three grand went out on aggregate this time round. That’s way better than in 2024 where 18k of the then total bill was for material added and removed, but still a fair whack of money: between that and the soil removal, we’re talking six to seven thousand euro on trucks bringing or removing material.
Total cost
Back in the very early days we had €40k as the PC sum for site preparation and groundworks. Here’s what was actually spent:
- 2022: €6,810 inc VAT for two days of works.
- 2024: €25,537 inc VAT for five days of works, of which ~€18k was for aggregates and soil removal.
- 2026: Estimated €30,000 inc VAT for nine days of works, which includes maybe €5k worth of roofing materials and €7k for aggregates and soil removal, so maybe €18k went on labour plus materials and digger & dumper hire. The digger probably cost €550 per week, the dumper €300 per week, so maybe €2.5k went on hiring those and maybe €3k if including diesel. Another €5k might have gone on pipe materials etc, so €10k remains for wages, insurance, profit margin etc. Assuming a €400 per day worker cost including payroll taxes, that leaves about a €3k profit margin. That’s fair enough, I know I wouldn’t do a job for less than a ten percent profit margin.
So, if I remove the roofing materials, that’s a total cost of ~€57,000 for site preparation and groundworks, rather more than anticipated – though, to be fair, cost estimates pre-covid are barely comparable to today’s costs in anything, let alone construction materials.
What’s next?
We need a topographical survey of the as-built site, as my drone and laser level are only accurate within maybe 50 mm and a professional survey should come in within 10 mm.
We then need the builder to get some building onto this site! Tomorrow four years ago we got planning permission for this build. That means exactly ONE YEAR REMAINS until planning permission expires. So people really do need to get a move on now.
The second topmost left IC may be too high to allow toilet flushes to work correctly, if the engineer thinks so then that IC and surrounding pipes will need to be relaid. We’ll see what they say next week.
Finally, I expect next week my children will stain the left boundary wall with a ‘dark oak’ colour – I would call it ‘chocolate’ colour myself, but ‘dark oak’ is what it is called. It should take them four coats and therefore four days to complete: to save money, they’ll be applying three coats of the cheapest possible stain, followed by a fourth topcoat of the expensive stuff. The cheapest possible stain is not actually that terrible, it separates quickly at rest, so it needs a vigorous agitation before every time you use it. After that it is a bit thin, but that also means it dries quickly and it soaks into the wood well. Three coats onto bare wood produces an acceptable stain albeit still a bit blotchy (we know because we tested it on plywood sheets). The fourth coat of expensive stain should eliminate the blotchiness, also the expensive stain has some polyurethane in it so the final finish kinda has a plasticky varnishy feel to it, resembling a kind of matte varnish. I’ve used it before on park benches, you do get at least five years out of it and probably more – it begins to look raggedly after five years, but almost certainly would last at least another three years before peeling. So I believe their tin’s claims that you can expect ten years of wood protection. The cheap stain makes no such claims, it says three to five years depending on rain exposure. Fair enough for the price – it is less than one tenth the price of the expensive stain.
After they stain the left boundary wall, they have various camps for the next two weeks, then I intend to have them paint the right boundary wall in textured masonry paint. That stuff is a pain to work with, but it lasts forever on the wall and produces a very good finish. It is normally hideously expensive, but Screwfix will sell you one tub per shop per two weeks at €50 inc VAT per tub as a loss leader. So, if you need five tubs as we shall need, you laboriously go accumulate them over months which I’ve been doing and I now have all the tubs I think we shall need to complete the job.
In between painting, especially if the weather is nice, I expect to repeat the e-bike jaunts we did last summer around North Cork. It’s such a pretty part of the world when in sunshine. Thankfully, we live right in the middle of it, and I intend to make the best of it for another summer.
Word count: 4792. Estimated reading time: 23 minutes.
- Summary:
- A detailed technical diary entry is presented. The imposition of new EU tariffs on small packages from China is discussed, and the resulting costs are detailed. Furthermore, various electronic components — including PWM dimmers and ESP32 development boards — are reviewed. Technical issues, such as fuse failure in DC-DC converters and fibre network testing setups, are also explained.
Thursday 25 June 2026: 14:08.
- Summary:
- A detailed technical diary entry is presented. The imposition of new EU tariffs on small packages from China is discussed, and the resulting costs are detailed. Furthermore, various electronic components — including PWM dimmers and ESP32 development boards — are reviewed. Technical issues, such as fuse failure in DC-DC converters and fibre network testing setups, are also explained.
This new tariff has been designed to be especially awkward and annoying: the foreign seller must collect a tariff deposit in advance, then pay it to the EU based delivery service who then may ALSO charge an additional administration fee. There are already reports of some EU national postal services charging over €20 as their admin fee, then the tariff is €3 + VAT per type of item, and that is on top of the original price in China plus EU VAT. This will render most small packages from outside the EU utterly uncompetitive in price, never mind lots of faffing around, delivery delays, and hassle.
Anyway, all that is a separate story told better elsewhere than this website, rather, this diary entry is about the end of an era: the Chinese direct to consumer market was primarily about price, but it was also about choice because sites such as Aliexpress often had components you simply couldn’t get elsewhere in small quantities, or indeed sometimes you couldn’t get them at all anywhere else. I, having known that this tariff was coming and being almost certain that the two weeks beforehand would be just a mess, got my ‘last ever’ Aliexpress order in by end of May, and the last of everything was successfully delivered without any hassles nor problems more than a week ago. This diary entry will review some of those recent orders.
I put ‘last ever’ in quotes because I will almost certainly buy some items from Aliexpress et al in the future, specifically items where I can’t get them anywhere else at all, or in reasonably sized quantities, or where even with the tariff they’re still cheaper than say Amazon which lists many of the same items, just 15-20% more expensive (I note that the Amazon commission is 15% for most items, as compared to 8% for Aliexpress). So let’s call this a review of my ‘last ever cheap Aliexpress order’.
Missing bits for the house
I had previously made large orders during the Singles Day sales, having spent thousands of euro on things like LED strips and DC PWM dimmer wall switches. I saved an absolute fortune over buying locally, but as the house design reached completeness we had become short in a few items e.g. DC PWM dimmer wall switches, as we had added a few more. I therefore made an order for the balance:
- Seven more DC PWM dimmer wall switches, which I previously reviewed here.
- Thirteen more BTS7960 H-bridge motor drivers, which I previously reviewed here.
- Sixteen more GA12-N20 motors with movement encoders, which I previously reviewed here.
These had all gone up in price by about 20% since the original order three years ago, apart from the BTS7960 H-bridges which were actually marginally cheaper. 20% is probably about the amount of accumulated price inflation during those three years, plus I was buying now in non-sale times whereas previously during the biggest and deepest annual Aliexpress sale. So, methinks fair enough.
This wasn’t an expensive order, I had had to keep meaning to get round to it for yonks, but the coming tariff made me get it done.
New type of DC PWM dimmer wall switch
While I was searching for my previously bought DC PWM dimmer wall switches in order to buy more of them, I found a model I hadn’t previously seen, and at under €12 inc VAT each they were nearly half the price of the ‘fancy’ ones I’ve standardised upon. I reckoned buying one was worth a punt so I could test it, and here it is:


The front panel is glass, which is surprising at that price point, and the knob is some sort of metal infused plastic which looks cheap and I’m not sure if the silver isn’t paint which would rub off over time. The build quality is noticeably below that of my ‘fancy’ model, and the circuit board is clearly simplified, however for a less often used location I think it would last years well enough. On the circuit board, there is a single 80N03 MOSFET – which is surprising as eighty amps seems rather overkill for this – and a 8S003F3P6 STM8 microprocessor, which is also surprising as it’s quite expensive relatively speaking at US$0.32 per unit. I unfortunately didn’t take a picture of the rear where the voltage converter obviously must live given the three pins pointing through, but it would be surprising if it’s much different to other DC PWM dimming wall switches: it’ll take something like zero to thirty volts input and output something between 3v and 5v (the STM8 will work with anything in that range). I certainly can confirm it works fine with 5v inputs as well as with 24v inputs.
How well does it perform? It turns out really well …


Yup, that’s a 80 kHz PWM being emitted there, which is ten times better than my ‘fancy’ switches which put out an 8 kHz PWM – and that’s great compared to cheap PWM dimmers some of which can run as low as 0.5 kHz. For this price point, that’s stunningly good, in fact it’s the best PWM dimmer off Aliexpress that I’ve ever personally seen. Why they don’t advertise this quality in the listing I don’t know, but certainly the choice of the expensive STM8 which has a 16 Mhz clock speed makes it trivially easy to emit an 80 kHz PWM, even if that is just a dumb loop manually pumping an output. The STM8 does have three hardware PWM outputs, it’ll do a divisor up to 32,768 on your choice of either a 16 Mhz or a 128 kHz internal clock. I’ve no idea how they implemented it, but such an overkill choice of expensive microcontroller makes very high quality PWM a cinch.
I can also tell you that there are exactly twenty stops on the dial between fully on and fully off, and when it’s off it connects everything to ground and puts itself to sleep (I can tell this, because I can see the noise from the AC-DC converter when the switch is set to off). I assume it writes its last known value to flash, as across a power cut it restores its brightness before losing power. As you can see on the oscilloscope, there is a nasty negative voltage flyback on PWM down, but as LEDs are also diodes and the negative flyback voltage is within 2x of the LED strip voltage, it should be fine. The ‘fancy’ switches reviewed nearly three years ago also have some negative flyback voltage, but more controlled than you see here.
For €12 inc VAT there is a lot to like here. If the knob were just a touch better quality, this model would be a no hesitation recommendation, and they are nearly half the price of my fancy model, so this is a whole load of DC PWM dimming knob for your money. I would still prefer my ‘fancy’ model not just for the better build quality, but also because it shows a dot LED when off so people can find it in the dark, and it does also show a percentage on a LED display, which is fancy.
Ultra ultra cheap PWM LED dimmer
Ever wondered to yourself how bad these ultra ultra cheap inline PWM LED dimmers are when you buy them in bags of ten or more and they come out at less than sixty cent each delivered (well, before the EU tariff anyway)?

The case is actually heat shrink wrapped plastic, and they have a standard DC plug. They can not only dim, but also do various flashing patterns. They do remember their last setting after power loss, but I know from experience with these cheap parts in the past that after a while they forget their last setting after power loss, no doubt due to flash write wear as they’ll use a single location for storage and not update a ringbuffer which you’d do to greatly extend life. At sixty cents each, you just replace them if the memory loss annoys you.
I wasn’t expecting much, but they turned out to be okay:
That is a 1 kHz PWM, not great but also not terrible. Some with sensitive eyes might see flicker if this were driving a large, bright, LED, but in general you would use these inline dimmers in something like a desk light or other small lighting solution. So flicker shouldn’t be that noticeable, even to those sensitive to PWM flicker.
The irony is not lost on me that this ultra ultra cheap PWM dimmer produces the cleanest oscilloscope graph of any of the PWM dimmers tested. Of course the sedate 1 Khz clock rate helps hugely with that, controlling flyback with a 80 kHz PWM clock rate is much harder than for 1 kHz. However, my picture also tells lies – this unit actually oscillates between really bad flyback and clean over time, and my picture shows it when it is behaving. Again, back voltage remains under 1.5x of LED strip voltage, so it’ll be fine, but you get what you pay for.
And also in that vein, this dimmer only has eight levels of dimming! This may be too few for some, but for sixty cents each they’re good value for money.
Thermistor surge protection
I don’t think that I’ve mentioned on here an issue with one of my 480w DC-DC converters which keeps blowing its fuse – what’s weird is that I have several of those converters in use, and only one location keeps blowing its fuse. I opened one of the failed units to discover why:

One of the blown DC-DC converters with its resin scraped out by me to determine why it failed
As you can see, it has a 20 amp automotive fast blow fuse on its 48-60v input, and from inspection I can see that is has blown. There appear to be two Aishi R series 63v 330 μF capacitors on the input side, and two LF ET series 25v 470 μF capacitors on the output side. The input side capacitors have a 0.041 ohm impedance at 100 kHz, and a rated ripple current of 1500 mA. I must admit some surprise that the fuse blows, as a 20 amp automative fuse actually has this blow curve (italic values are inferred by continuing the slope of the line on the datasheet):
| Amps | Duration to blow | |
|---|---|---|
| 30 | 5 seconds | |
| 40 | 400 milliseconds | |
| 50 | 200 milliseconds | |
| 70 | 100 milliseconds | |
| 100 | 50 milliseconds | |
| 125 | 25 milliseconds | |
| 150 | 12 milliseconds | |
| 175 | 6 milliseconds | |
| 200 | 3 milliseconds | |
| 225 | 1.6 milliseconds | |
| 250 | 0.8 milliseconds | |
| 275 | 0.4 milliseconds | |
| 300 | 0.2 milliseconds |
For 54v DC to create a current above 20 amps would require a resistance below 2.7 ohms, but the lower the resistance the shorter the duration of surge current. Let’s say that the resistance is one ohm, then from 660 μF of capacitance the surge current would be 54 amps and it would last 3.3 milliseconds – nowhere near long enough to blow that fuse. Therefore, the resistance must be way lower, enough to generate such a massive current flow that it could melt that fuse. Let’s divide by ten and see what happens:
| Resistance | Surge Current | Surge Duration | ||
|---|---|---|---|---|
| 1 ohm | 54 amps | 3.3 milliseconds | ||
| 0.2 ohm | 270 amps | 0.66 milliseconds | ||
| 0.1 ohm | 540 amps | 0.33 milliseconds |
And now I think we have our cause: you would need to get that resistance down to the 0.1 ohm range to blow that fuse. I have a 16 mm2 cable feeding that power supply, and now I come to think of it that is unique: all the other power supplies have a much thinner wire connecting them, and maybe that is just enough to have protected them so far?
In any case, back when I bought the thermistors I wondered if I could ‘soft start’ the DC-DC converter using a thermistor and prevent the fuse blowing? Aliexpress lets you buy small bags of basic electrical components easily and cheaply, so a bag of fifty of these turned up for only a few euro delivered:

This is the MF72 2.5D13 thermistor, and it has 2.5 Ohms of resistance when cold (25 C) and 0.088 Ohms at 200 C, which it should reach quickly. At its steady state current of six amps once at 200 C, it would therefore dissipate about 3.17 watts of power. As a variable resistor, it therefore initially restrains current when first switched on, then it heats up, and as its resistance falls more current is allowed to pass and the heating of the thermistor reduces until it reaches a steady temperature.
I hadn’t figured out the cause of the DC power supply blowing its fuse at the time of ordering, so to be honest I sized those based on knowing that if the input voltage is 54v and a 20 amp fuse is getting blown, then a 2.5 ohm resistor ought to cap current flowing to 21.6 amps. As exterior temperatures in Ireland are very rarely 25 C at night time, you should actually get a good bit less than 20 amps in the real world. The D13 size came from the steady state current of six amps, which as 70% of the maximum draw of this DC converter (~8.5 amps of 54v) would be the likely maximum load I would allocate to these.
Now that I do know the cause, the thermistor is definitely oversized. You only need 0.1 ohms of additional resistance to not melt the fuse, so a MF72 0.7D25 thermistor would be a better choice as it would waste up to six times less power. Still, losing a few watts on a 200w load seems reasonable if it saves me having to constantly replace DC power converters.
How quickly does the thermistor get hot? I got out my backup 54v DC power supply, and put one of these thermistors between the 54v supply and the 48-60v to 24v DC-DC converter. I then placed my battery load and capacity tester on the 24v output. It’s probably easier to show pictures of the test setup:


The power supply actually outputs 55.4v, and yes I did confirm this during testing. My battery load tester will only load up to 184 watts, so I firstly ran a test at 0.1 amps which is 2.4 watts on the output side. With conversion losses, that is at least 2.67 watts going through the thermistor:


With the thermistor at ~23 C, one should be getting around 2.5 ohms resistance so if the voltage drop is 0.198v and the current flowing is 0.048 amps, resistance should be 4.13 ohms. That’s obviously a lot more than expected, however at very low current flows the relative losses in the DC-DC converter will be high, so if say current flowing on the input side were actually 0.07 amps now you’re getting a resistance of 2.83 ohms and that feels more like it. If so, power lost to heat would be 0.014 watts, or 0.6% – this being so low because the thermistor does not radiate much heat into the environment.
Ramping it up to the maximum 180 watts which is about 200 watts on the thermistor:


The thermistor is now a toasty 130 C and the voltage drop is 0.66v. Current flowing through the thermistor should be around 3.61 amps, so power lost to heat would now be 2.38 watts, or about 1.2%. Resistance should be about 0.183 ohms, or about twice the resistance if the thermistor were at 200 C according to its datasheet.
When I first applied the 200w load, I noticed the voltage drop across the thermistor was momentarily 4.3v before rapidly falling within a second or two to less than 0.7v. If so, resistance was somewhere around the 1.2 ohm mark for whatever fraction of a second that was, and power lost to heat would have been 15.5 watts. No wonder that the thermistor gets hot so quickly!
If you leave the load tester off, the thermistor sits at about 20 C just over the ambient temperature. The parasitic draw of the unloaded DC-DC converter wastes very little heat in the thermistor. This is good to know. At a 100w draw which is probably around 110w for the thermistor, it reaches 92 C (I didn’t take a voltage drop).
Most of these DC-DC converters will be deployed into the LED strips for the outdoor lighting. The easiest solution is to run thinner wires to them which will offer the necessary protection against current surges: let’s say I fit 1.0 mm2 diameter wire, this would have a max amperage of 8-17 amps with a 4.24 volts per amp drop per 100 metres. 10 metres of such cable would offer 0.166 ohms of resistance, plenty more than the 0.1 ohms we need – so if I make sure I fit at least five meters of no thicker wire than 1.0 mm2 diameter, no more fuses will blow!
Modern fibre network testing with the Fluke LRAT-2000
Many years ago I picked up at vast cost a used Fluke LRAT-2000 which is an ethernet wiring validation tool. The LRAT-2000 was launched around year 2012, and it cost many thousands of euro – you could buy a used car for the price of a new LRAT-2000. Even used on eBay today fourteen years later, they still cost over a thousand euro which is quite remarkable given that all they do is (i) test each of the wires for being correctly connected (ii) helps you figure out which cable in a bundle is connected to which (iii) test that TCP traffic flows over the cable (iv) test PoE power loads. Why did I splash out such money like so many others on eBay still do for such legacy hardware? Simple: the quality is guaranteed to be there, so when it tells you that an ethernet cable has a break eighteen metres along, you can be confident that is where the break is before you take a kanga hammer to your wall.
One feature that it supports is fibre network testing. For this you need to insert a compatible fibre transceiver into the LRAT-2000’s SFP cage. As this is such old hardware, the fastest network supported is 1 Gbps and it turns out that a gigabit speed fibre transceiver in the legacy SFP format costs about €45 each even off Aliexpress, and of course you need two of them. €90 felt a bit steep for testing the eight or so fibre cables which are likely to be installed in my future house, so I looked for an alternative.
A few years ago I fitted 2.5G fibre transceivers as the backhaul between my Wifi 6 access points, these being the fastest possible for the legacy SFP (not the newer SFP+) cage – these were under €10 each, and they run with a relatively low power draw and very much tick the box for the problem they solve (distance backhaul). Years ago I bought a tray of those transceivers enough for all my future needs lest they fall out of production and become expensive, however of course the LRAT-2000 is too old to use those (it does recognise them if you plug one in, but it can’t find a network). What I therefore needed was some sort of box which let me connect the LRAT-2000 to a newer fibre transceiver, and it turns out that Aliexpress has exactly such an item: a cheap dumb media converter box which sends layer 2 network frames from one SFP+ cage to another. You then plug in whichever transceivers you want to have fibre to fibre, ethernet to fibre or ethernet to ethernet. There are also variants with a single SFP+ cage, and a RJ45 ethernet port.
(To be clear, you can also get branded media converter boxes from all the usual vendors e.g. TP-Link, but the unbranded models – which appear to be physically identical from pictures apart from a printed logo – are, or at least were before the tariffs, a good bit cheaper)
I ended up buying the following before the tariffs came in:
- Two 10G ethernet to SFP+ media converter boxes each for €38.33 inc VAT delivered.
- Two 10G single mode LC fibre transceivers for a fairly astonishing €7.71 inc VAT delivered. Yes, that’s a 5 km capable 1310nm wavelength ten gigabit transceiver for under a tenner.
And while this solution involves more wiring and power adapters than I would prefer, it does solve testing fibre connections with the LRAT-2000:

This was about the same cost as two of the legacy 1G fibre transceivers, so I didn’t save money – however I think this spend of ~€100 better bang for the buck.
High speed fibre transceivers have become ridiculously cheap in recent years: 40G fibre transceivers cost about €12 each, even 100G fibre transceivers are just €25 each. That makes 100G networking very feasible for a home network, which is just madness: the entire country of Ireland had 25G of international connectivity as late as year 2003. That’s 4x the entire former international connectivity of Ireland in your home!
What remains expensive is > 10G wired ethernet, as are > 10G switches. You can avoid expensive wired ethernet by fitting an inexpensive PCIe to SFP+ cage adapter to your PCs/servers and running fibre between everything, but a 10G switch with SFP+ cages is still a fair sum of money: Amazon currently lists an eight 10G ethernet port switch with SFP+ cage for €136 (albeit, it is managed not unmanaged). If you want faster than a 10G switch, used commercial switches are in the hundreds of euro range, but they are very loud and burn a lot of electricity; if you want something quiet and power efficient, it currently costs many thousands of euro. Given this, you may actually be better off building a cheap low power PC and filling it with PCIe to SFP+ cage adapters, however 40G ethernet SFP+ transceivers are not cheap nor do they sip power. One option is a switch of 40G SFP+ cages, these appear to be on sale used for about €500 right now, so you could probably build something somewhat quiet and power efficient for under a thousand euro if you populated that exclusively with 40G fibre transceivers. Still, that’s a thousand euro! Better than 10G networking remains a four figure cost for now.
And to finish, yet another bag of ESP32 dev boards …
If there is any iconic product line where Aliexpress has been absolutely stonking value for money it has been ESP32 dev boards. Two years ago I bought a bag of ESP32-C3 ‘Super Mini’ dev boards delivered and including VAT for €1.50 each. As described at the time, there were even cheaper dev boards on Aliexpress, the very decent RP2040 cost just €1.29 inc VAT delivered, but in terms of compatibility with a large existing microcontroller software ecosystem the ESP32 is hard to beat.
Before cheap Aliexpress went away forever, I therefore had a look around to see if any of the higher end ESP32 dev boards had come down to bargain basement prices, and indeed they had: there is now an ESP32-C6 ‘Super Mini’ dev board with most of the worst design mistakes in the C3 ‘Super Mini’ dev board fixed and those also come in bag sized quantities for tens of euro:

Comparing the C3 and C6 models directly:
| Board | Price I paid | CPUs | RAM | Flash | Wifi | Bluetooth | LR-WPAN | GPIO | Additional |
|---|---|---|---|---|---|---|---|---|---|
| ESP32-C3 Super Mini | €1.50 inc VAT in 2024 | 1x 160 Mhz RISC-V | 400 Kb | 4 Mb | v4 (2.4Ghz) | 5.0 | No | 13 | Blue LED |
| ESP32-C6 Super Mini | €2.74 inc VAT in 2026 | 1x 160 Mhz + 1x 20 Mhz RISC-V | 512 Kb | 4 Mb | v6 (2.4Ghz) | 5.3 | Yes (Zigbee, Thread etc) | 17 sides + 5 central | RGB LED, Battery charge |
The C6 is about 60% more expensive after adjusting for inflation. The C6 board is also available with a 8Mb flash variant (and it costs 4x more) which is useful if you want to run a Zigbee controller. But in essence, the C6 is the C3 except with a modern 2.4 Ghz radio hardware module implementing IEEE 802.15.4 which is a software defined wireless networking. This lets software easily implement many wireless networking protocols, such as Zigbee, Thread, Matter or anything similar. Wifi also gets modernised in the C3, going from Wifi 4 to Wifi 6, albeit still with only a 2.4 Ghz radio. And I suppose that the dev board does have 70% more i/o exposed, plus a lithium battery charge controller, if any of those things matter to you then the +60% cost may be worth it. Here is the C6 board right next to a C3 board for comparison:

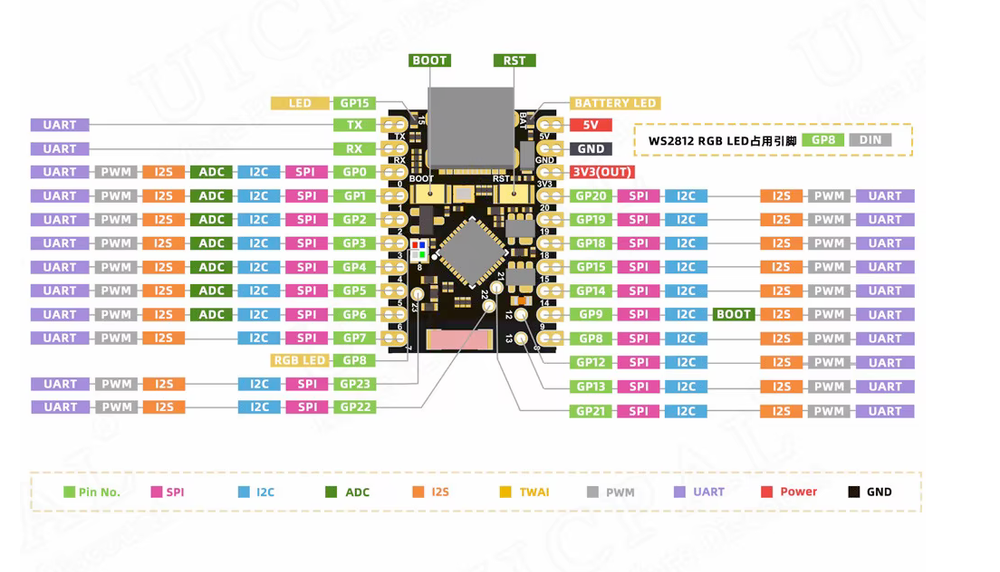
For me, the main attraction of the C6 is for Zigbee routers (these extend a Zigbee network) and battery powered Zigbee end devices. Zigbee active consumes about 23-80 mA, and a Zigbee router needs to always be active, so one of my 3000 mAh lithium batteries would last only one hundred hours – still, if you had a Zigbee dead zone, firing in one of these with a bit of wire soldered onto its antenna to greatly extend range would bridge the issue, with low running costs when wired in for power.
Probably more exciting are battery powered Zigbee end devices e.g. a temperature sensor which could be dropped wherever you need them without having to wire them in. Zigbee end devices can deep sleep between periodic wakes to push data. Deep sleep on the C6 ‘Super Mini’ dev board can get down to 55 uA if you remove the RGB LED which always burns 330 uA even when off AND make sure you supply at least 3.6v to the battery pin/5v power input, otherwise the voltage buck converter burns current and it’ll horse through your battery quickly. If running off a battery, make sure to monitor the battery voltage and self disable if it gets below a certain minimum e.g. 3.4v, otherwise this board will happily run your battery down to damaging levels of empty.
The C6 has a proper low power 20 Mhz CPU for deciding whether to wake the board up or not which might be useful. The C3 has fixed function wake logic, so for example you might say ‘if pin A rises wake me’ which you can also do on the C6, but only wake the 20 Mhz CPU. It only has 16 kB of RAM accessible to it, but it CAN speak i2c and UART which is good enough to deal with a large subset of sensor boards. You could do fairly complex filtering or decision making with the 20 Mhz CPU, and wake the 160 Mhz CPU and wireless stack only if it were really necessary. This could shave off a few more percent of battery consumption.
According to real world numbers I researched from the internet, one of my 3000 mAh batteries fitted to a sleepy Zigbee end device and with a typical i2c sensor waking every ten minutes might last 10,000 hours = 1.14 years. When its battery gets low, you simply plug it in via USB and it’ll charge itself to full, then you can redeploy it. I can’t currently think of when I might use such a thing, but for the few euro to buy a bag of the C6s now before cheap Aliexpress ends it is definitely worth the hedge.
What’s next?
Most of this entry was written at the site while popups were installed. Expect a full write up and lots of pictures next entry!
Word count: 1446. Estimated reading time: 7 minutes.
- Summary:
- The input is a combined diary entry and a highly technical guide. A dark theme implementation is described, where pure CSS variables are utilised. Automatic switching based on the operating system’s theme can be achieved using
@media queries. Furthermore, a manual override is demonstrated via checkbox hacks, although significant code duplication must be accepted for the feature to be fully operational.
Thursday 18 June 2026: 07:40.
@media queries. Furthermore, a manual override is demonstrated via checkbox hacks, although significant code duplication must be accepted for the feature to be fully operational.
- Summary:
- The input is a combined diary entry and a highly technical guide. A dark theme implementation is described, where pure CSS variables are utilised. Automatic switching based on the operating system’s theme can be achieved using
@mediaqueries. Furthermore, a manual override is demonstrated via checkbox hacks, although significant code duplication must be accepted for the feature to be fully operational.
This post introduces the most radical style change to this website since the Hugo conversion back in March 2019: a dark theme which is automatically chosen by your web browser if your system’s theme is dark. If your system is configured to switch between light and dark themes based on time of day, so will this website. If you wish to override the current light-dark theme chosen, there is now a floating theme override button in the top right of the page. It works identically on mobile and desktop, and requires no Javascript: it is pure CSS only.
Major browsers gained this ability around 2020 and it works like this: Firstly, we replace all the colours in all the CSS with CSS variables, which have been available in major browsers from 2017 onwards:
/* light */
:root {
color-scheme: light dark;
--c-body-bg: #fff;
--c-body-fg: #000;
--c-navbar-bg: #fff;
--c-navbar-divider-bg: #000;
--c-hover-bg: rgba(0,0,0,0.1);
--c-hover-fg: #FF0000;
--c-hover-glow: #aa0000;
--c-tooltip-bg: beige;
--c-tooltip-fg: #000;
--c-tooltip-border: chocolate;
--c-tooltip-arrow: #000;
--c-pre-bg: rgba(0,0,0,0.05);
--c-quote-bg: rgba(0,0,0,0.05);
--c-shadow: #aaa;
--c-shadow-heavy: #000;
--c-affiliate-border: #000;
--c-post-details-border: #000;
--c-link: #00e;
--c-link-visited: rgba(85, 26, 139, 1.0);
--c-toggle-bg: rgba(255,255,255,0.33);
--c-toggle-fg: rgba(48,48,48,0.66);
--c-toggle-border: rgba(48,48,48,0.33);
--c-toggle-shadow: rgba(0,0,0,0.33);
--c-toggle-hover-bg: #fff;
--c-toggle-hover-fg: #333;
}
I actually had Step 3.7 Flash do most of this work, and it chose for the
CSS variable names a c- prefix for reasons I don’t precisely understand,
but equally it seemed a safer thing to do so I left it.
We now use the prefers-color-scheme CSS feature to tell the browser
to overwrite those variables when the system theme is dark:
/* Experimental CSS5 stuff */
@media (prefers-color-scheme: dark) {
/* dark */
:root {
--c-body-bg: #000;
--c-body-fg: #fff;
--c-navbar-bg: #000;
--c-navbar-divider-bg: #aaa;
--c-hover-bg: rgba(255,255,255,0.2);
--c-hover-fg: #FF0000;
--c-hover-glow: #ff6666;
--c-tooltip-bg: #2d2d2d;
--c-tooltip-fg: #d4d4d4;
--c-tooltip-border: #555555;
--c-tooltip-arrow: #555555;
--c-pre-bg: rgba(255,255,255,0.2);
--c-quote-bg:rgba(255,255,255,0.2);
--c-shadow: #333;
--c-shadow-heavy: #000;
--c-affiliate-border: #444444;
--c-post-details-border: #555555;
--c-link: lightskyblue;
--c-link-visited: #ad8bcd;
--c-toggle-bg: rgba(32,32,32,0.33);
--c-toggle-fg: rgba(240,240,240,0.66);
--c-toggle-border: rgba(240,240,240,0.33);
--c-toggle-shadow: rgba(255,255,255,0.33);
--c-toggle-hover-bg: #222;
--c-toggle-hover-fg: #eee;
}
Finally, you add to the <head> stanza to tell the browser that you support
automatic theme switching <meta name="color-scheme" content="light dark">,
and you will now have automatic theme switching, where the default theme is
light.
Making the theme user toggleable
Sometimes you might not want the theme to be dark or light depending on use case, so being able to override it manually is a must. You can do this trivially easy using four lines of Javascript, but I wanted to avoid Javascript so that unfortunately means stamping out quite a lot more CSS:
/* CSS-only dark mode toggle overrides via checkbox */
/* light */
#theme-toggle:not(:checked) ~ #page {
--c-body-bg: #fff;
--c-body-fg: #000;
--c-navbar-bg: #fff;
--c-navbar-divider-bg: #000;
--c-hover-bg: rgba(0,0,0,0.1);
--c-hover-fg: #FF0000;
--c-hover-glow: #aa0000;
--c-tooltip-bg: beige;
--c-tooltip-fg: #000;
--c-tooltip-border: chocolate;
--c-tooltip-arrow: #000;
--c-pre-bg: rgba(0,0,0,0.05);
--c-quote-bg: rgba(0,0,0,0.05);
--c-shadow: #aaa;
--c-shadow-heavy: #000;
--c-affiliate-border: #000;
--c-post-details-border: #000;
--c-link: #00e;
--c-link-visited: rgba(85, 26, 139, 1.0);
--c-toggle-bg: rgba(255,255,255,0.33);
--c-toggle-fg: rgba(48,48,48,0.66);
--c-toggle-border: rgba(48,48,48,0.33);
--c-toggle-shadow: rgba(0,0,0,0.33);
--c-toggle-hover-bg: #fff;
--c-toggle-hover-fg: #333;
}
/* dark */
#theme-toggle:checked ~ #page {
--c-body-bg: #000;
--c-body-fg: #eee;
--c-navbar-bg: #000;
--c-navbar-divider-bg: #aaa;
--c-hover-bg: rgba(255,255,255,0.2);
--c-hover-fg: #FF0000;
--c-hover-glow: #ff6666;
--c-tooltip-bg: #2d2d2d;
--c-tooltip-fg: #d4d4d4;
--c-tooltip-border: #555555;
--c-tooltip-arrow: #555555;
--c-pre-bg: rgba(255,255,255,0.2);
--c-quote-bg: rgba(255,255,255,0.2);
--c-shadow: #333;
--c-shadow-heavy: #000;
--c-affiliate-border: #444444;
--c-post-details-border: #555555;
--c-link: lightskyblue;
--c-link-visited: #ad8bcd;
--c-toggle-bg: rgba(32,32,32,0.33);
--c-toggle-fg: rgba(240,240,240,0.66);
--c-toggle-border: rgba(240,240,240,0.33);
--c-toggle-shadow: rgba(255,255,255,0.33);
--c-toggle-hover-bg: #222;
--c-toggle-hover-fg: #eee;
}
This is unfortunately very copy-and-paste, but I am unaware of doing better using pure CSS. In any case, we now overwrite those CSS variables based on whether the toggle theme checkbox is checked or not. Unfortunately we are not yet done with the copy-and-paste:
/* Experimental CSS5 stuff */
@media (prefers-color-scheme: dark) {
/* CSS-only dark mode toggle overrides via checkbox */
/* dark */
#theme-toggle:not(:checked) ~ #page {
--c-body-bg: #000;
--c-body-fg: #eee;
--c-navbar-bg: #000;
--c-navbar-divider-bg: #aaa;
--c-hover-bg: rgba(255,255,255,0.2);
--c-hover-fg: #FF0000;
--c-hover-glow: #ff6666;
--c-tooltip-bg: #2d2d2d;
--c-tooltip-fg: #d4d4d4;
--c-tooltip-border: #555555;
--c-tooltip-arrow: #555555;
--c-pre-bg: rgba(255,255,255,0.2);
--c-quote-bg: rgba(255,255,255,0.2);
--c-shadow: #333;
--c-shadow-heavy: #000;
--c-affiliate-border: #444444;
--c-post-details-border: #555555;
--c-link: lightskyblue;
--c-link-visited: #ad8bcd;
--c-toggle-bg: rgba(32,32,32,0.33);
--c-toggle-fg: rgba(240,240,240,0.66);
--c-toggle-border: rgba(240,240,240,0.33);
--c-toggle-shadow: rgba(255,255,255,0.33);
--c-toggle-hover-bg: #222;
--c-toggle-hover-fg: #eee;
}
/* light */
#theme-toggle:checked ~ #page {
--c-body-bg: #fff;
--c-body-fg: #000;
--c-navbar-bg: #fff;
--c-navbar-divider-bg: #000;
--c-hover-bg: rgba(0,0,0,0.1);
--c-hover-fg: #FF0000;
--c-hover-glow: #aa0000;
--c-tooltip-bg: beige;
--c-tooltip-fg: #000;
--c-tooltip-border: chocolate;
--c-tooltip-arrow: #000;
--c-pre-bg: rgba(0,0,0,0.05);
--c-quote-bg: rgba(0,0,0,0.05);
--c-shadow: #aaa;
--c-shadow-heavy: #000;
--c-affiliate-border: #000;
--c-post-details-border: #000;
--c-link: #00e;
--c-link-visited: rgba(85, 26, 139, 1.0);
--c-toggle-bg: rgba(255,255,255,0.33);
--c-toggle-fg: rgba(48,48,48,0.66);
--c-toggle-border: rgba(48,48,48,0.33);
--c-toggle-shadow: rgba(0,0,0,0.33);
--c-toggle-hover-bg: #fff;
--c-toggle-hover-fg: #333;
}
}
What we are doing here is flipping the handling of the toggle theme checkbox being ticked based on the system’s current theme i.e. you get the system’s current theme on page load, if the system theme changes the website also changes its theme, and the toggle theme checkbox being ticked therefore means ‘the opposite theme of the system theme’. Next we need a theme toggle:
<input type="checkbox" id="theme-toggle" class="theme-toggle" aria-label="Toggle dark mode">
<div id="page">
<label for="theme-toggle" class="theme-toggle-label" aria-label="Toggle dark mode">
<span class="icon-moon" aria-hidden="true">🌙</span>
<span class="icon-sun" aria-hidden="true">☀️</span>
</label>
...
</div>
Thanks to Unicode, the sun and the moon no longer need dedicated image assets like we would do in the bad old days. Nowadays, you just use the appropriate Unicode codepoint, dead simple.
The next thing is to make our toggle theme button NOT have a visible checkbox, and to style its label so it shows the moon or the sun and that floats at the top right with a transparency so it doesn’t get in the way of reading text:
/* Visually hidden checkbox but keyboard-accessible */
.theme-toggle {
position: fixed !important;
top: 0;
right: 0;
height: 1px;
width: 1px;
overflow: hidden;
clip: rect(1px, 1px, 1px, 1px);
}
/* Fixed floating dark-mode toggle button */
.theme-toggle-label {
position: fixed;
top: 1rem;
right: 1rem;
z-index: 9999;
width: 2rem;
height: 2rem;
border-radius: 50%;
background: var(--c-toggle-bg);
color: var(--c-toggle-fg);
border: 2px solid var(--c-toggle-border);
display: inline-flex;
align-items: center;
justify-content: center;
cursor: pointer;
font-size: 1.2rem;
line-height: 1;
box-shadow: 0px 0px 8px var(--c-toggle-shadow);
}
.theme-toggle-label:hover {
background: var(--c-toggle-hover-bg);
color: var(--c-toggle-hover-fg);
border-color: var(--c-hover-fg);
}
.icon-moon,
.icon-sun {
display: inline;
}
Finally, we need the toggle theme icon to be the correct one in all circumstances, which unfortunately requires yet more copy-and-paste CSS:
.theme-toggle:checked ~ #page .icon-moon {
display: none;
}
.theme-toggle:not(:checked) ~ #page .icon-sun {
display: none;
}
@media (prefers-color-scheme: dark) {
.theme-toggle:checked ~ #page .icon-moon {
display: inline;
}
.theme-toggle:not(:checked) ~ #page .icon-sun {
display: inline;
}
.theme-toggle:checked ~ #page .icon-sun {
display: none;
}
.theme-toggle:not(:checked) ~ #page .icon-moon {
display: none;
}
}
And that’s basically it – an unfortunate amount of duplication in the main CSS file, but it does get served to users gzip compressed so all that text duplication matters little to website load times. Most processors are so fast at parsing text that the extra verbiage doesn’t really matter either. As I mentioned above, you could use a few lines of Javascript and save yourself all this duplication, but I personally configure my web browser with Javascript disabled by default and I enable it on a per-site basis – only if I absolutely must use a site and it’s broken without Javascript do I enable it. If it’s a site I don’t care hugely about and it won’t load without Javascript I generally just close the tab, not worth the effort.
As mentioned above, Step 3.7 Flash did almost all of the work here. It didn’t get quite all the way there on its own though, because I wouldn’t let it install web page to image rendering via which it could debug its work. So I took it manually for the final stage of debugging and tweaking to get the last of it over the line. But I understand from reading online that if I had allowed it to visualise the results of its work and to click around the web page by itself, it should have successfully completed its task in full. The reason I didn’t give it the power to browse and interact with web pages by its itself alone is probably obvious: I hadn’t set up safety containerisation for it on my Mac, so it was effectively operating as if me.
It’ll probably be popups installation in my next diary entry. Depends on when they get it completed and what the weather will be like in the next few days. We shall see!
Word count: 1723. Estimated reading time: 9 minutes.
- Summary:
- The final entry regarding the balcony solar installation has been written. After delays caused by smart meter outages, data analysis was completed. It is found that the solar panels contribute to bill reduction. An annual saving of €204, representing an 11% decrease in electricity costs, is estimated. The return on investment period has been calculated at 2.54 years.
Monday 15 June 2026: 17:02.
- Summary:
- The final entry regarding the balcony solar installation has been written. After delays caused by smart meter outages, data analysis was completed. It is found that the solar panels contribute to bill reduction. An annual saving of €204, representing an 11% decrease in electricity costs, is estimated. The return on investment period has been calculated at 2.54 years.
How much money is this ‘balcony solar’ installation saving me in terms of bills?
This is because the Irish ESB Networks makes public your smart meter data with a delay of a few days, but not infrequently they have outages which delays that data by weeks. We unfortunately had one of those outages end of May, and I didn’t get complete smart meter data for analysis until today.
Quick recap
You will remember from the first post that current electricity costs and tariff distribution are as follows:
| Period | Current cost per kWh | Summer daily avrg | Winter daily avrg |
|---|---|---|---|
| Peak rate: 5pm - 7pm | €0.38 (+65% over night rate) | 1.93 kWh (€0.73) | 2.41 kWh (€0.92) |
| Day rate: 8am - 5pm, 7pm - 11pm | €0.33 (+43% over night rate) | 8.81 kWh (€2.91) | 9.80 kWh (€3.23) |
| Night rate: 11pm - 8am | €0.23 | 3.15 kWh (€0.72) | 3.30 kWh (€0.76) |
And that:
- 66.7% of the bill goes on day rate electricity.
- 16.7% of the bill goes on peak rate electricity.
- 16.5% of the bill goes on night rate electricity.
So, from a bills perspective, you only really care about day rate and peak rate electricity as that is 83.5% of your electricity bill.
Furthermore, that two solar panels were first hooked into the house mains from around mid-April, with those being initially ground mounted and left to run for a few weeks while I debugged the setup and made sure it would all work before going to the bother of installing them onto the outhouse roof. From the 8th May onwards I had all four panels mounted onto the outhouse roof and contributing power. The configuration is that three panels are connected to the battery storage and one panel is connected to the inverter on its second input – from 9.30am each morning the battery charges to full and a single panel supplements household electricity usage; once the battery is charged, all four panels supplement the household usage; from 5pm onwards the battery discharges at 220 watts with the single panel supplementing, until 11pm when everything turns off until 8am in the morning when the battery again outputs 220 watts with the single panel supplementing. One should therefore save at least two kWh of day and peak rate electricity per day in the summer months, and I had been expecting a theoretical saving of around twenty percent of day + peak rate electricity usage during those summer months. That, based on the 83.5% of my electricity bill above, should reduce my bill by 16.7%, or about €25 per month, but again only during the summer months where there is enough free energy falling from the sky to fully charge the 1.6 kWh battery storage each day.
The last two years at the mains meter box
Note that the Irish ESB only provide the last two years of detailed data from your smart meter:


I’ve separated daylight savings time (DST) months from winter months (GMT) because the seven months of DST are the only ones from which you’ll get much off solar panels, and even then March has been considerably better than October for solar radiation in the past two years. DST also matters because you switch on lights earlier and later in the day, so you tend to use more power during GMT months. Which leads me into …
Confounding factors
The most natural thing to do would be to compare last year’s electricity consumption to this year’s, however last year before June I had the main developer workstation turned on daily, and this year past I mostly don’t have it turned on daily as my Macbook is enough for most of the things I need to do if I’m not earning money (e.g. right now, I’m writing this on the laptop plugged into the developer workstation’s large 4k monitor, because spinning up the dev workstation to type text is way overkill). In 2024, an average typical summer day + peak rate used 11.62 kWh and an average typical winter day used 12.25 kWh, whereas after unemployment an average typical summer day + peak rate used 9.67 kWh (-16.82%) and an average typical winter day used 12.18 kWh (-0.6%).
I must admit a little surprise that I had the developer workstation turned on so frequently during the most recent winter months, but that does match my memory – I remember being quite grateful, as I am every year, for the free space heating my office gets from the developer workstation being turned on. The fact that this adds more than one eighth to my total household electricity bill is a little sobering, but at least heat generated by the workstation is a more productive use of that electricity than an electric bar heater.
I should also mention that immediately after my employment ended, I particularly was not at home as I was out riding bikes and climbing mountains during June and July 2025, so the electricity for those months was lower than it likely will be this year where I’m more accustomed to having my freedom, for example.
What is the estimated reduction of my electricity bill?
Obviously the yellow bars in the summer months chart above for April, May and June 2026 are our reductions from the ‘balcony solar’. After adjustment for my unemployment reducing power consumption anyway, I reckon that the solar panels contributed a reduction in peak and day rate electricity consumption according to the ESB meter box as follows:
| Month | Reduction |
|---|---|
| June 2026 | -22.96% |
| May 2026 | -13.89% |
| April 2026 | -2.54% |
May is probably lower than it should be because my APSystems EZ1 inverter’s MPTT1 input died, so I had to route everything through its MPTT2 input only. That reduced efficiency by a bit – judging by June’s results so far, by quite a bit in fact. In June a replacement was installed and the original sent back as RMA, so we’ll see how things go in the next few months.
Assuming that you will only get much from the panels for seven months, and that winter months use more power, I reckon I might get an annual electricity bill reduction of around eleven percent. That is, in my case and with current electricity prices, equal to €204 saved in bills per year. That is a return on investment period of 2.54 years, a bit longer than I had originally intended (a year!).
Why so low? This 2023-era low voltage system is particularly inefficient, I reckon it loses a good 20-25% of the power it captures, plus it doesn’t charge optimally, nor does it discharge optimally. A 2025-era or later system based on dual inverters so it is capable of simultaneous charge and discharge would be considerably less stupid with power distribution, and it would respond to changes in household consumption rapidly, rather than wastefully sitting at a constant discharge rate between fixed time periods irrespective of the weather outside.
As covered in previous posts in this series, for a little more money you can get FAR better kit, modern stuff instead of this 2023-era kit that I ended up with thanks to Aliexpress sending me not what I had thought I had ordered. As we’ll probably be out of this rented house within 2.5 years – well, hopefully! – I’m going to lose money on this project. But for anybody reading, if you expect to still be living where you are right now for more than two years, you really ought to be very strongly considering installing micro solar generation into your house. Even in Ireland’s typically overcast skies! Solar battery storage has gotten so cheap it’s a no brainer.
This is despite zero subsidies from the government (indeed, a 23% VAT tax on all the equipment!), and zero payment for excess power contributed to the grid. Even with those very unfavourable conditions, microgeneration solar is face palm obviously the right move with a two year payback period, as year three onwards is pure gravy.
What’s next?
The popups installation for my site has begun! I’ve been waking at 4am to be onsite for 6.30am this week to help out, as I will be tomorrow morning. Thank God I am unemployed! And expect an entry on here with pictures when it’s all done.
I asked the Step 3.7 Flash LLM how it would improve this website. It gave a long list of modern web page design ideas, none of which interested me, bar one: a dark-light theme which auto switches based on your viewing device’s dark-light theme setting (apparently this landed with CSS v5, I don’t pay attention to new web standards until somebody – or some LLM – points stuff out to me). So I went ahead and implemented that dark-light theme for this website, and you can expect an entry on that soon.
My ‘end of an era’ special on Chinese direct to consumer sales platforms like Aliexpress is probably after the dark-light theme entry, though an entry on the site popups installation might beat it. In any case, I hope to get that end of an era entry up before the end of the month when the EU tariff comes in as then would be timely.
Other than those three, I don’t have any particular plans for diary entries here. School for the kids ends tomorrow week, after which I’ll be on childcare until end of August, and I’ve been tempering my expectations about getting anything else done appropriately. I expect plenty of bicycling around North Cork’s spectacular scenery on the e-Bikes as with last year, but also upcycling furniture (the kids will be learning how) and painting walls (the kids will also be learning how). I’m sure between all that the summer will fly and before we know it they’ll be back to school.
Who knows if my builder will turn up and erect my house by then! I suspect it very unlikely, but we’ll find out.