What is "Tornado"?
- Uses data components & streams as the programming model instead of object orientation
- Removes the user interface productivity wall
- Guarantees future-proof code for next 30 years
- To sum up:
- The fundamental focus of the whole Tornado project is to make your computing experience, whether it be using or programming, as productive as possible - both now and well into the future.
I'm afraid what I can put here is becoming increasingly limited, but
should I get some funding all that will change. If you want some laughs
you can see the old Tornado II
documentation here. At least, if nothing else, I can say I wrote more
documentation this time round
![]()
Many of the problems caused by proprietary software are not ones I wish to repeat; however GPL software has its own worrying long-term implications as well. I have set out all of this plus my views on how Tornado's licence could look like here.
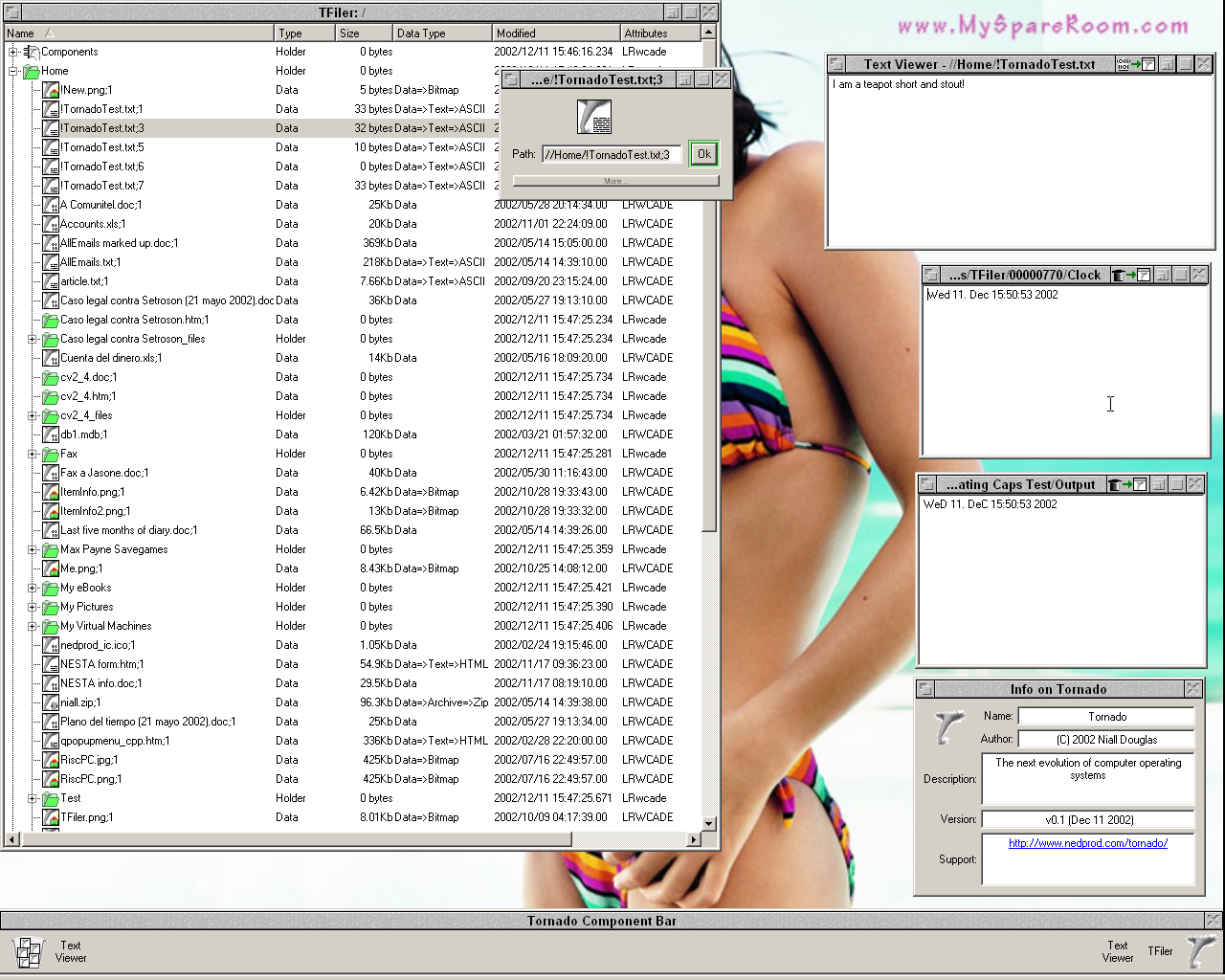
Above is screenshot of Tornado III. Another screenshot is here, Screenshot of Tornado II here, and Tornado I here.
{kind=link}
Project journal:
Thursday 9th January 2003:
3.57am. Code is unchanged, so same line count as last time. Well no one
wanted to even see me for an interview regarding my project, so all funding
opportunities have been denied to me. Hence I am now in the process of
moving to the UK where there's (a) money via work and (b) a much better
network of contacts with whom I could form my company. Upshot of this of
course is that Tornado could not be brought to the world now for perhaps as
long as four years ![]()
Of course, development will continue in my spare time, albeit at a much reduced pace. Next major step is implementing Tornado menus, the current hacked Qt versions aren't useable long-term. After that comes write support, scripting via Python and then component support. If I get that list done, I will be very close to being API fixed and thus I could employ other programmers to help me.
I bumped into another RTOS today called QNX. It's been extended to provide a form of data streams so that brings the total of Tornado-like systems to two: Plan 9 and QNX. I see that an old favorite of mine AtheOS is now called Syllable and is enjoying a substantial lease of new life - it'll probably have data stream like extensions too shortly. No doubt, the computer software world is moving towards data streams as the next paradigm, though I still bet Tornado will vastly eclipse all of these due to it being several evolutions further removed again - plus, of course, it's ground-up designed rather than bolting on to an existing paradigm.
Well, I don't know when there'll be another entry in here. Unlike in the past though, I fully intend to keep hacking away at this one until one way or another my legacy to the computer world is ready. I want to be remembered in posterity!!!
Wednesday 11th December 2002: 3.39pm. Current line count: 21719 (total: 29930). As you can see above, it now properly looks like its own operating system. One in theory could replace Windows Explorer or indeed KDE with Tornado and it would look and operate almost identically to a real operating system based on Tornado. However, since we still don't have component support there aren't any icons and the left side of the bar doesn't work yet as it should.
The one other thing I may add depending is bitmap support. It's a fairly trivial thing given Tornado is so wonderfully extensible. Depends greatly how many bites upon the hook the fishes make really, and when.
And well, that's that. Many more bugs in the kernel fixed, it's now sufficiently stable I never need to restart it when I'm testing the client apps. It's all good.
Thursday 28th November 2002: 9.24pm. Current line count: 20617 (total: 28576). Well, we're nearing the end of this stage. I'm approaching the point where more or less the project is ready for demonstration, indeed for the last few days I've been mostly fixing bugs and I don't expect that to change before the end significantly.
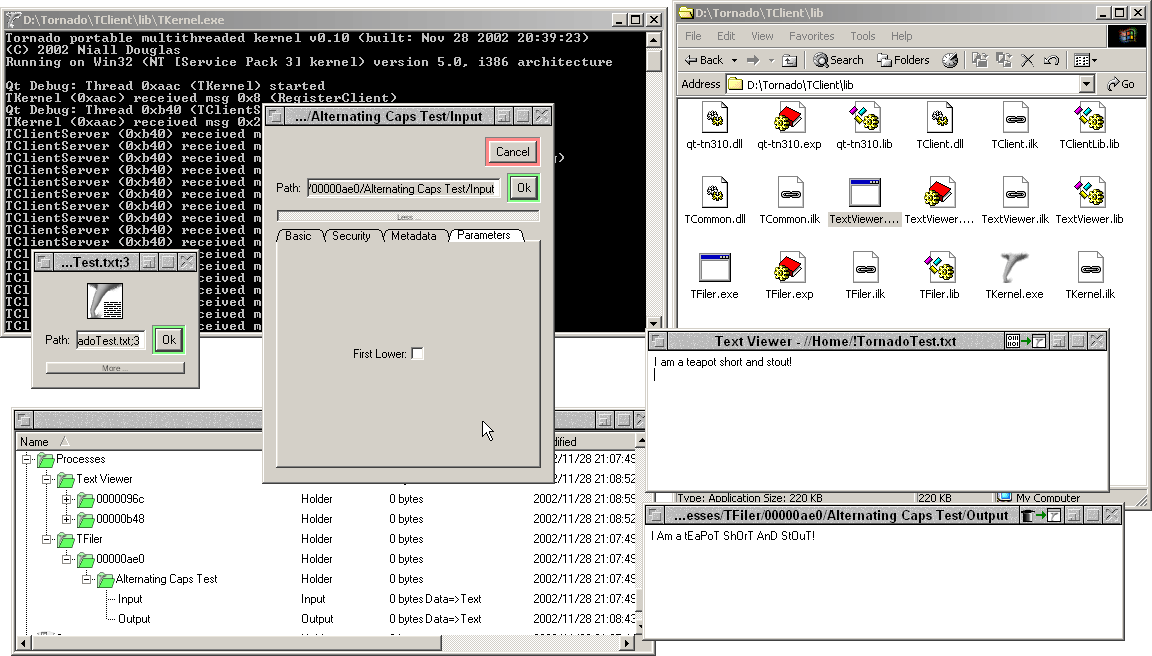
It's a big old picture above, but since it'll be the last one here and thus more or or less a permanent fixture I put extra effort into it (though, I've just noticed I forgot to open an example of the interactive help, but never mind). I can't really explain the new features here as it could be argued they fall under patentable technology, but suffice it to say you can now drag and drop loads of stuff from any one particular place to any other particular place. Also, as you can clearly see, the kernel and client processes now live on their own instead of as threads within the one executable. I've been doing some benchmark tests, and totally unoptimised data streams can transfer around 3.2Mb/sec on my machine which is well faster than 100Mbit ethernet, so I'm well happy.
I've also been testing on my old 400Mhz AMD K6-3 and it runs well there via VNC. While there are still pauses for a quarter second or so, it runs pretty fluidly on the older machine and interestingly the same pauses happen on my new machine, so it looks like a temporary deadlock or time out more than over processing.
It runs perfectly the first time you do something, but it's still acquiring a history and occasionally not liking stuff getting freed or killed off. There's still some memory corruption in the kernel, but I personally think it's QDir rather than my own code. What it gets seriously annoyed about is if an exception fires off and some stuff is getting killed in a way it shouldn't do - but I'm slowly ironing out those problems. Nevertheless, 90% of the time all sorts of horrible things can happen and it handles it correctly!
I've been putting a lot of time into the prepatory materials such as presentations. I'm planning to start soliciting funds within the next two weeks, basically once the demo is sufficiently stable I feel I can distribute it. And then, well, it'll be Christmas again.
Wednesday 14th November 2002: 8.34am. Current line count: 17695 (total: 23854). Mark this day as historic! Yes, less than fifteen minutes ago tornado data streams worked for the very first time!!!
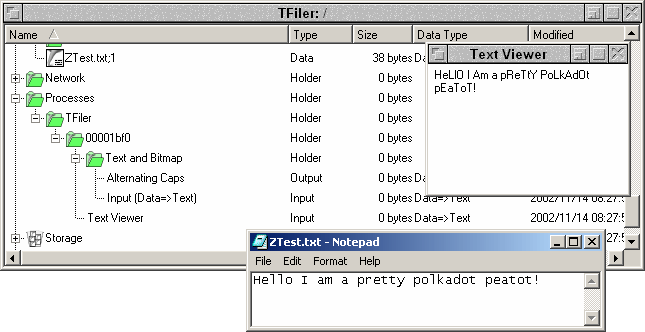
As you can see, processes can now have connection points which can be either inputs or outputs and these can be categorised. Above, TFiler has an input and output in the category "Text and Bitmap" (yeah I forgot to change the name). What isn't depicted here yet (it's coming) is that there is a data stream connecting "ZTest.txt;1" at the top to Input, which then offers the output "Alternating Caps". There is then a further data stream connecting that output to "Text Viewer" which is of course the window called just that on the top right.
So, basically, not only do I have two data streams working together but I also have a primitive data converter because the input point is (as you can see) alternating capitalisation of the input data. The original, obviously, is in the Notepad window.
Now there's a whole pile of other cool stuff streams can do, but I'm not going into it here as it could be called disclosure of patentable information. Suffice it to say they are everything I promised and plenty more besides, and certainly for read only purposes they work a treat already.
What comes next? Well, currently there aren't any locking semantics, the code is there but it isn't tested. Then comes write support, then comes graphical representations of stream connections so you can see at a glance what's connected to what. I'd also like to do some benchmarking, creating the streams currently takes about a second or so and that's too long.
Then comes rudimentary component support. It'll be extremely basic, but sufficient. I also want a rudimentary Tornado taskbar working too. If I really hammer it, I may get all this done by the end of the month, leaving December for business proposals - sending, debating and much thinking.
Right, time for the Sopranos. I've earned it!
Saturday 2nd November 2002: 2.18am. Current line count: 15400 (total: 21205). Well, I'm here. I'm actually here. And on schedule - just as I predicted the project would reach end of phase 2 at the end of October (phase 1 was design, phase 2 was infrastructure):
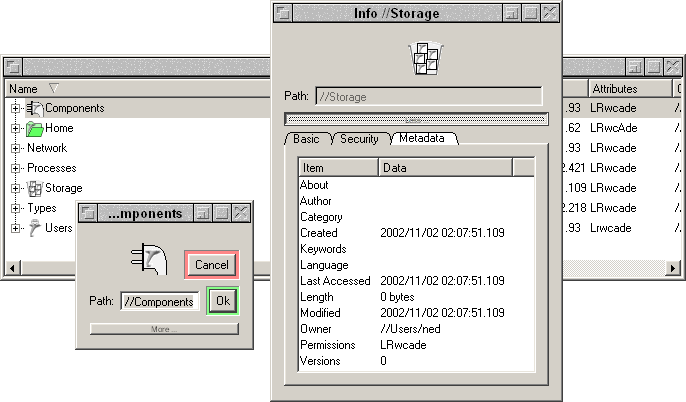
There isn't much difference in appearance from the last screenshot, but there is actually a world of difference. I have done lots of testing these last few days, trying to see where and how I could make it trip up. As to be expected with a work in progress, it did trip up and so I fixed it. From the "forgetting to delete things from the cache" to "only updating one cache, not all three" bugs to that thread deadlock one I mentioned last time (actually, one was in my RWMutex code - failed to write promote readers - and the other is in Windows itself - believe it or not, the function to output debug strings isn't threadsafe!) to performance enhancements (asynchronous updates were calling synchronous functions - doh! And I now set a spin count on all mutexs, and I can actually see the difference), extra features (eg; security checks, renaming files, creating new files, deleting files, altering versions, setting metadata) I can honestly place hand on heart and say "she's ready, gov".
Weekends being what they are means I won't probably get properly started on phase 3 till Monday. I also have barely any food or money due to me being burrowed in here all week and yet another surprise national holiday appearing today, so everything was shut. The basic plan is to start on the data object framework first - they'll have a base class defining the interface and subclasses will do all the actual work - this is so I can reuse the code kernel side as well as client side. Likely difficult parts will be the connection interface - these are like typed sockets you can connect to and what output points are available depend on the input(s). They have to be as completely type-dependent and as little component-dependent as possible to maintain component transparency.
Once I have data objects mostly working, I can repatch in my (very old now) datastream code. It'll need some serious revising to make it work with the current system, but it's design is mostly good. Then after loads of testing, I should be ready for some first ever basic component which I think will convert a JPEG into a PNG. And after all that, I'll be needing some viewer widgets which basically are inbuilt viewers of the tornado fundamental types.
All goes to plan, by mid-December I should be able to double-click on some data and it'll appear in a viewer window. That'll be my cut-off point for going for venture capital.
Tuesday 30th October 2002: 12.42pm. Current line count: 14179 (total: 19763). Well, screenshot first:
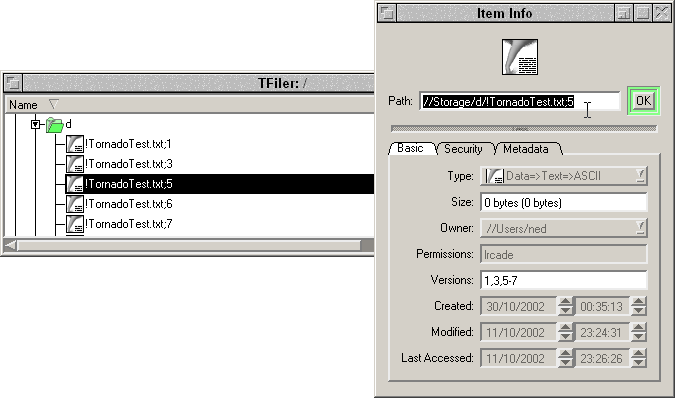
This is the project running as though it were on Unix with motif (though in fact it was running on Windows). As you can see, we now have a natty item information box but in fact it does way more than it appears to. Yes, you can drag the icon. Yes, it supports multiple files and the dragging of them too. Versioning now works, as can be seen and also directory change notification also works - deleting and creating files in the host OS appear immediately in the display. Because of Windows' crapness with change notification, I had to create a thread per directory watched so the thread count spirals upward pretty quickly. Unlike Windows, POSIX doesn't support setting the thread's stack to something small, so I'll have to use a different approach on Unix (though how is unknown - Linux issues signals of all things so it'll be interesting how to dispatch those).
Also of course the new info box is a type editing box. There is the facility to make all those entries writeable and then you can change them, the idea being I can now test writing metadata. Once that's working of course, I'm now into fun-land with data objects.
So, that's that. I may add security descriptor translation support still, or I may just issue a default. I am tempted to push for data objects sooner rather than later and despite a bug during shutdown where there's a thread deadlock (annoyingly unrepeatable) the code seems robust!
Oh, I added a sales brochure. Enjoy!
Tuesday 22nd October 2002: 8.52am. Current line count: 12831 (total: 18060). Yes, I am up this late in the morning, while I was pulling my hair out over drag & drop in Qt I moved to awakening around 8pm. Today I'll fix this, need to go to the bank which shuts in five hours!
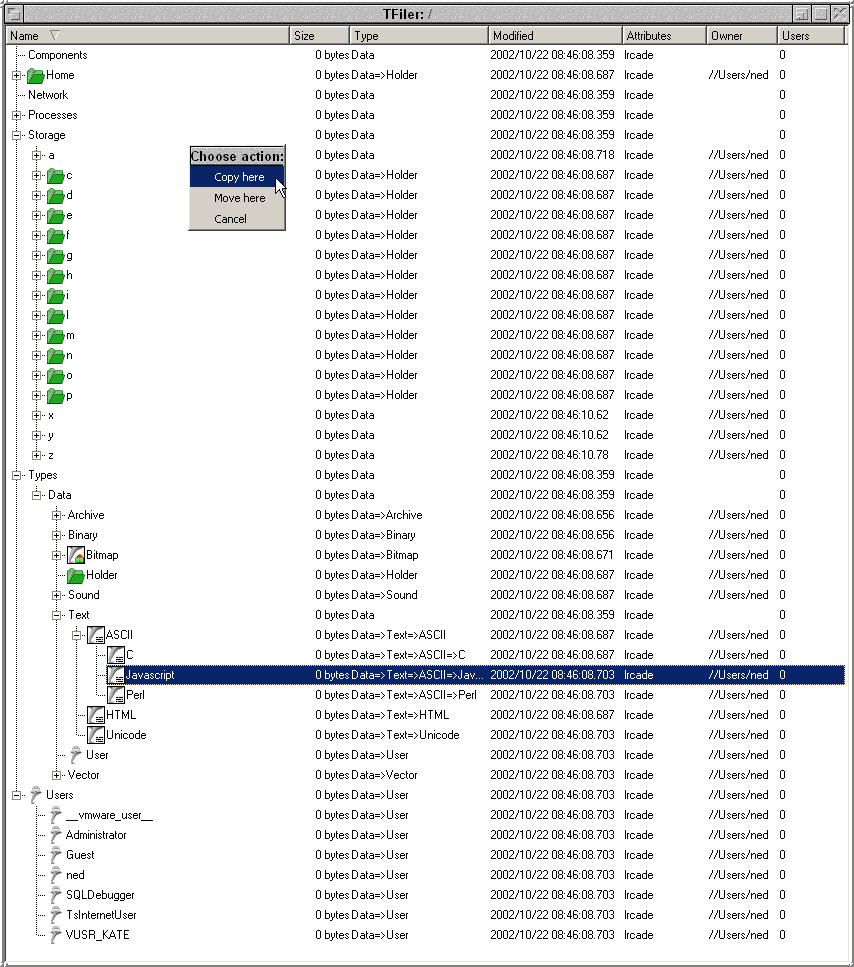
Well, we now have all promised last update. As you can see above, the kernel now translates file extensions into Tornado types and their associated MIME types. It furthermore now has icon support which you can also see above, and yes, you can drag and drop any item inside any Tornado application outside or vice versa. Dragging can either copy/insert, move/open or popup a menu asking depending on which mouse button or combination of Ctrl and Alt is depressed.
I furthermore heavily optimised the host OS file system mapping routines. A 2000 entry directory used to take 14 minutes to translate, now it takes four seconds. I added node caching with dynamic resizing based on system free memory, so once opened once it can now be accessed in a third of the time. I also added user and type representations to the kernel namespace which you can see above also.
Next up? Well, there are still a few small bugs. A friend is arriving shortly so I won't be able to put in the 12 hour days I have recently. I think next is testing change notification ie; when a host OS file changes, do the changes appear in the list automatically? The code is written, just disabled. Then comes write support - creating, copying, setting types, metadata etc.
Then, my friends, comes the first venture into blue-sky research land - the very first time such a concept to my knowledge has been used - Tornado kernel data sources and Tornado data streams. I don't expect to have these fully working until the end of November, thus leaving me precisely a month to make it into a demonstrable system for venture capitalists.
I think I can do it!
Thursday 18th October 2002: 5.17am. Current line count: 11220 (total: 15815). Well she certainly grunts along now! With all the added code plus me doing things properly instead of quick and dirty has meant fetching metadata for an item now hovers around 500ms rising rapidly to 900ms as you nest downwards say maybe three levels. Hence I split the metadata fetching off into a separate thread which asynchronously updates the display as and when they arrive - this provides jerky but continuous use, at least up until you throttle the connection with the kernel and everything begins to seriously slow down ... anyway, I also finished my menu hacks, they look ugly but they do work enough for my testing purposes:
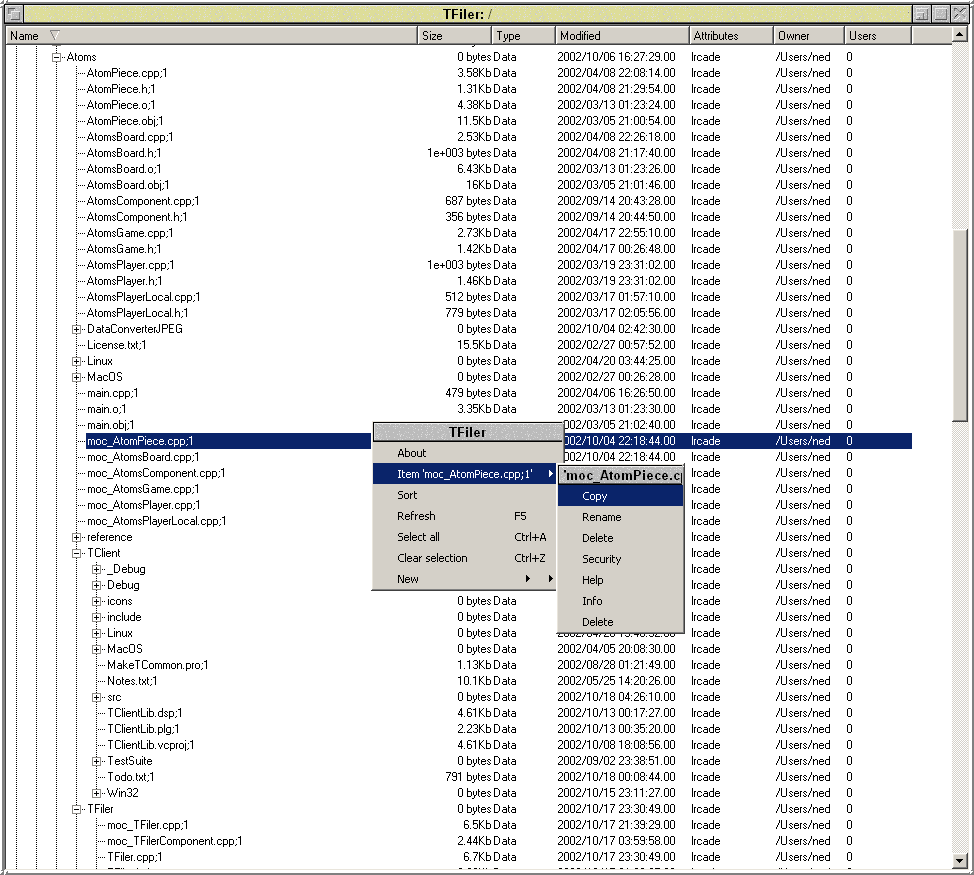
The menu hacks were particularly nasty - even writing data into private members of Qt classes using hardcoded pointer writes. I know I'll have to go rewrite the whole menu system some day but for now I merely need something with which to call test routines, and what I have done is mostly API compatible with what I intend to rewrite. So, it's all good.
Next big thing on the cards is the data type database which is responsible for mapping MIME types, filename extensions and Tornado data types against each other. After that I may need to implement node caching because for some odd reason MSVC7 produced executables run less than half the speed - so literally through a simple recompile (still in Debug mode) in MSVC6 and the lot runs much more nippier. My thoughts are that this is good - if it runs quickly in Debug mode, it'll be lightening quick in fully optimised Release build. Hopefully :)
After that I'll need to test change notification. In theory, it should notice when a host OS file changes and update anything interested in it. In theory. I've devised a cunning accumulation routine which should accumulate changes and when it all goes quite for a second it notifies the client with the block of changes. In theory :)
Wednesday 9th October 2002: 5.19am. Current line count: 10001 (total: 14537). Well, it's all cooking now isn't it! Not only have we broken the 10k line no mark, we also have loads of new code to enumerate the kernel namespace and have clients notified when changes occur on items the client has an interest in. I also made a start on TFiler, the Tornado kernel namespace viewer. And well, it all works, here have a look see at the first ever screenshot for this attempt at least:
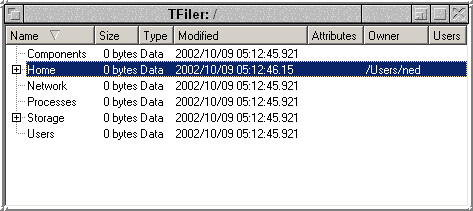
Yeah I know about the ugly borders, that's cos I manage my own resizing as Qt was curiously unhappy to do it for me. Hence the borders were drawn using a primitive because I had to see them to drag them!
Also, obviously, the only parts of the namespace which work are /Home and /Storage. In fact, the filer can't even open sublistings as yet, and there's a clear lack of metadata too. But all that's coming.
I also made a start on the nested menu system I've had an idea for. Basically, you don't define a menu, you define your localised entries relevant to your little widget. Then when the user opens a menu, the window collates the entries together greying out the ones which aren't applicable - thus achieving a vastly superior menu user interface.
It's hard to explain just how much shit is going on underneath the bonnet of displaying the above window. Yeah, I know I've said that before about screenshots of previous Tornado attempts, but this time it's really true, honest! The two to three seconds it takes to open the window is the booting of the kernel, client establishing a connection to the kernel and then you actually reach the TFiler initialisation code which does loads of caching - which makes sense as it'll almost always be in memory.
Anyway, I'm tired. I've been at this ten hours a day more or less since the weekend. Time for bed!
Saturday 5th October 2002: 8.08pm. Current line count: 8859 (total: 13184). Last night I had the wonderous vision of the Atoms game (the little experiment in Qt on which I began my experiments) actually popping up and more importantly staying up for an extended period. Unfortunately as yet she won't shutdown correctly, there was a problem with POSIX threads cleanup and object destructors getting called recursively for which I'll need a rewritten solution.
All in all, I'm very impressed I managed to debug that much new virgin code in only three weeks. I'm sure that while there will still be some nasty surprises awaiting me, I now have a solid framework on which to build layer after layer of new functionality.
The first plan is lots of testing of kernel namespace code - benchmarking it as well of course. Then I need to test all of that with multiple threads, possibly add a namespace node caching system and such.
Then, when it's working, port the lot to Linux and get it working there too. There's some code in the OS abstraction layer I'm a bit suspect of being able to implement in Linux.
Once all that's done, then comes a filer app with which to navigate the namespace. Once I have that, then come data sources and data streams as I'll finally have a program to test them with comfortably. More or less by this stage I'll expect my time will be up. Work from here on in will have to occur in my spare time.
Saturday 14th September 2002: 9.30pm. Current line count: 8585 (total: 12857).
She compiles and links for the first time without error!
![]()
![]()
![]()
![]()
![]()
![]()
Tuesday 3rd September 2002: 12.08am. Current line count: 8503 (total: 12739). Apart from the two week break for my holidays, it's been nothing more than bugfixing since the last entry. This has taken two forms: rewriting badly written code and fixing bad grammar. I also have little realisations in the middle of the day about code which won't work (eg; my old security descriptor needed a complete rewrite which ate a good week of my time). I also discovered large sections of code in the kernel which were totally out of date, so I had to gut them and bring them into modern land.
I've also got started on the test suite, there currently are two: to test string and to test the multithreading bits. I had thought the latter would take ages given the constant rewrites but I'm glad to announce there were precisely two errors in the lot - amazing really - though one of those errors ate a good three hours (despite being blindingly obvious :( ).
Now I know TRWMutex works for sure, I can finish off TKernel which in fact is nearly compiling. I totally reworked TComponent to permit components to be loaded by other components as libraries, not thinking it's needed yet but better effort now than lots more later.
Tuesday 6th August 2002: 10.17am. Current line count: 8069 (total: 12098). TCommon now compiles, as does TClient and we're slowly getting there with TClientLib (though I need TKernel for it to fully link). However, as expected, there has had to have been substantial rewrites to not just the class structure but also some implementational detail as well. I have had to rewrite TProcess because it behaves slightly differently between kernel and client; I completely gutted the kernel messaging system and replaced it with the stuff I had written for data stream control, and there have been various realisations about dynamic in-place object construction which have been instructive; I am nearly finished rewriting TAccessPerms because the old one I realised wasn't threadsafe in that one descriptor could refer to other descriptors and of course there was nothing stopping that being in the process of being modified; there have been various other small class tweaks and rewrites because of a conversation with Marshall Cline.
Yeah, the highlight of the past week has been a daily intercourse with this fellow who has served on the ISO C++ standardisation committee and also wrote the C++ FAQ, an excellent document strongly recommended. I basically wrote with comments and this developed into a dialogue about OO programming, C++, Plan 9 & Limbo, data-centric program design, functional languages and plenty more including of course Tornado. I have compended this dialogue into the following document which may be of interest to people.
Basic future plan is to attempt to compile everything before the end of the week, at which stage I shall be taking my holidays until the 20th August. After that comes a test suite, I have lots of grunge code whose correct operation is very important and once it's working, I can map the data stream code back in and see how far we can take it.
Monday 22nd July 2002: 2.30am. No, I'm still at it! Even with a near two month gap, it's still progressing! Current line count: 7597 (line count last entry was including docs: if we do, that's 11097)
There's been lots of stuff which has got in the way of coding. Private matters have repeatedly arisen which have demanded my attention which my virtual diary details. I still had last entry to handle the court case and lots of other distracting stuff too, and it's all taken time. I have returned to the project piecemeal at intervals - I even took a full dump to Ireland with me in case I had free time to work on it there - but as it happened, I didn't.
On the technical front, I've recently had difficulties with the kernel namespace nodes in that originally I had them orphanable from the B-tree but then I realised that I didn't need to do that (I had assumed each node would be instantaneous and hence become out-of-date) if I made sure the nodes kept themselves recent. This made for a great deal of saving of complexity so that now every child node has a guaranteed unbroken line upwards to root - this fixes what some Unices suffer from when you request an absolute path and it takes milliseconds to retrieve the records as it goes to disc. I'm still not sure about the locking mechanism so I placed semantics for both per-node and global list in simultaneously, thus letting me choose later on really easily.
I've also had other little GPL projects on the way: SymLink and CallWin32. SymLink I've had planned since the start of Tornado III, it lets you create symbolic links on NTFS and I figured this the best way to map NT drive letters into the kernel namespace. Of course, I also wanted to use it to test my recently acquired copy of Qt/Windows 3.0 which Trolltech very kindly let me have with six months delayed payment and interestingly, I managed to find out a few things about the static library bind which Trolltech didn't know themselves yet. It's comes in at a minimum of 2Mb :)
CallWin32 was a little extension of Red Squirrel, an emulator for Acorn ARM series computers (which is what I grew up with and has most greatly influenced me - you'll see a lot of RISC-OS in Tornado). It permits RISC-OS code to execute arbitrary code in Windows, which has lots of very obvious uses. I implemented a little idle detector which returned processor time to Windows for example. The reason for doing this, other than helping myself when using Red Squirrel, is to refresh my assembler and ARM skills.
Anyway, I'm now finally ready to head for an executable at long long last. I hit the compile button tonight for the first time on TCommon and got back 574 errors! So, it's going to be a while even to getting a compile and then of course will come debugging. First test comes the kernel namespace, rigorous hammering of it. Once that's done, I'll patch in the data stream code and hammer it. Then comes a directory filer I think ... and then data converters. By which stage it should be at least six months from now, and I'll have a working technology demonstration.
Wednesday 29th May 2002: 11.11pm. Can't believe it's 11pm again. The entire day just seems to fly by recently, which is definitely a good thing. Things are most definitely coming together - the code I'm writing now not only is some of the finest code I have ever crafted (it is as efficient, flexible and maintainable as anything I have yet created) but the way forward has finally become clear in the last two days especially. I am now writing code with the sureness that save bug fixes, this is production code. No more messing around with conceptualisation and object hierarchy problems.
I will admit though some problems with my knowledge of C++. I wrote my first template class in my life yesterday to enable correct implicit data sharing across multiple threads making copies of an object. I've also run into a few problems with knowing when to use references and when to use pointers - I've twigged now that pointers are for pointing to a base class, references are for everything else. I've also had a few problems with mistakes or limitations of Qt which is annoying and required yet more code to fix the mistakes or implement missing functionality (eg; all those implicitly shared classes).
But all this aside, so far so good. I have the awful feeling I am going to break my record of most lines of code written without compilation. The last time I had a working executable I had some 4,707 lines of code and now I have 8,480 with that rapidly growing. I shouldn't be surprised if I exceed 5,000 lines with compilation, which is a hefty amount given that prior to that EuroFighter test bench project, the biggest I had ever written was ~8500 lines (that was the BBC Basic to C compiler BTW). It would certainly appear that very shortly Tornado will have become my second biggest project and given some luck, it should exceed 30,000 lines in the next five months (assuming I have enough money for that).
Right, relaxation time is beckoning. Still no internet connection, in fact I'm looking into getting a different one put in by another company. But I'll let you know.
Friday 24th May 2002: 1:44pm. I started this journal for two reasons: the first it that by writing out what I'm doing, it helps me think about it. The second is that I didn't want to fill my virtual diary with technobabble seeing as most of the readers aren't programmers, so I shifted the tech talk here.
Well, three weeks of full time programming down. When I started, I had barely any documentation at all, and I think you'll agree what I've produced so far isn't too bad at all. Furthermore, I also got the kernel messaging working, which took quite a while - stupid thing wasn't flushing the pipe before closing it, so about a third of the time the message got eaten.
Then, two weeks ago, I started one of the most difficult things I've done so far - the data stream code. This code is so vital to the success or failure of Tornado as an entire project that it has to be perfect because it's not exactly like I can tweak it later to improve it if it's got something wrong with it. That's the problem with backbone code, especially if it's difficult backbone code.
So yeah, all of last week went up in smoke either from me being sick with a viral infection (still wrote documentation during that though, despite being sick as a dog) or from me writing code one day and then deleting it all and rewriting it the next day.
Ok, so I hear you cry, that's symptomatic of poor design! And you'd be completely right! Just like with Tornado I and especially Tornado II, I am running into the design wall again because I really truly have no idea how data streams should be structured. I know what they need to do (a lot), but how that translates into efficient portable code still eludes me. And trust me, I have a sheaf of papers here with scribbles all over them with design after design which looked as good as I could make it until I began coding up the structure. And then suddenly, bam!, I get the horrible realisation that it won't work.
I've lost the last two days (but luckily no work) from some poor naming choices and forgetfulness. I had called a reference to kernel data TData and looking back on it, that was stupid. TDataRef is much better because it's a reference, not the actual data. No component owns their data, they only can maintain a reference to it. Unfortunately, I'd be working (oddly) to the assumption that it did contain actual data, but that was because I was confusing myself with the difference between local data and kernel data - often local data is a deendianised version of the kernel data broken into whatever its class says, which is unfortunate because it duplicates data. Unfortunately, unless you're clever with the file format design, I can't see any way around this - file data is intrinsically not the same as the exact same data in memory.
The main problem, as it's always been, is with conceptualising this project correctly. I can have pages of written notes going into each section in detail, but keeping it all correct in your head as you're writing it is another thing. Hence the TData/TDataRef thing - I didn't have that little "ref" to remind me it was a reference, not the actual data. Hence shit loads of stuff now has the wrong name or design, and I'll have to fix it all up now.
Well, I suppose mea culpa for not doing proper DFD's and such. Anyway, I'll finish off today with something nice and simple - TRWMutex.