 is a VERY fast, VERY scalable, multithreaded memory allocator with little
memory fragmentation. If you're running on an older operating system (e.g.
Windows XP, Linux 2.4 series, FreeBSD 6 series, Mac OS X 10.4 or earlier)
you will probably find it significantly improves your application's
performance (Windows 7, Linux 3.x, FreeBSD 8, Mac OS X 10.6 all contain
state-of-the-art allocators and no third party allocator is likely to
significantly improve on them in real world results). Unlike other allocators, it is written in C
and so can be used anywhere and it also comes under the Boost software
license which permits commercial usage.
is a VERY fast, VERY scalable, multithreaded memory allocator with little
memory fragmentation. If you're running on an older operating system (e.g.
Windows XP, Linux 2.4 series, FreeBSD 6 series, Mac OS X 10.4 or earlier)
you will probably find it significantly improves your application's
performance (Windows 7, Linux 3.x, FreeBSD 8, Mac OS X 10.6 all contain
state-of-the-art allocators and no third party allocator is likely to
significantly improve on them in real world results). Unlike other allocators, it is written in C
and so can be used anywhere and it also comes under the Boost software
license which permits commercial usage.It has been tested on some very high end hardware with more than eight processing cores and more than 8Gb of RAM. It is in daily use by some of the world's major banks, root DNS servers, multinational airlines and consumer products (embedded). It also costs no money (though donations are welcome!). Thanks to work generously sponsored by Applied Research Associates, nedmalloc can patch itself into existing binaries to replace the system allocator on Windows - for example, Microsoft Word on Windows XP is noticeably quicker for very large documents after the nedmalloc DLL has been injected into it!
It is more than 125 times faster than the standard Windows XP memory allocator, 4-10 times faster than the standard FreeBSD 6 memory allocator and up to twice as fast as ptmalloc2, the standard Linux memory allocator. It can sustain a minimum of between 7.3m and 8.2m malloc & free pair operations per second on a 3400 (2.20Ghz) AMD Athlon64 machine.
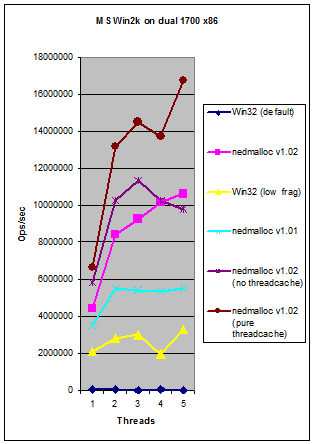
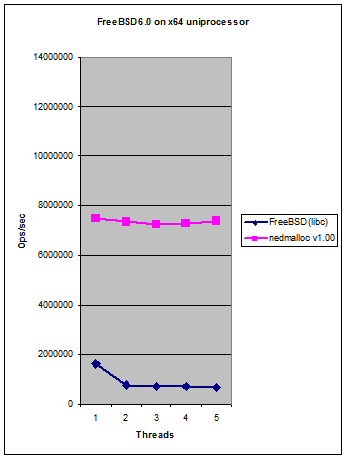
It scales with extra CPU's far better than either the standard Windows XP memory allocator or ptmalloc2 and can cause significantly less memory bloating than ptmalloc2. It avoids processor serialisation (locking) entirely when the requested memory size is in the thread cache leading to the kind of scalability you can see in the graph on the right. In real world code:
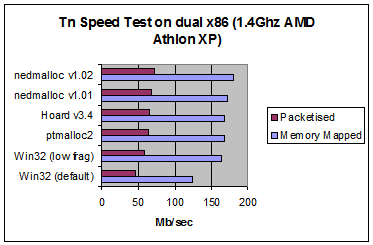
| Memory Mapped | Packetised | nedmalloc's Improvement | ||
| Win32 (default) | 123.72 | 46.29 | 45.38% | 54.03% |
| nedmalloc v1.02 | 179.87 | 71.3 | - | - |
| nedmalloc v1.01 | 172.47 | 67.9 | 4.29% | 5.01% |
| Win32 (low frag) | 164.28 | 58.74 | 9.49% | 21.38% |
| ptmalloc2 | 167.41 | 63.46 | 7.44% | 12.35% |
| Hoard v3.4 | 167.4 | 64.65 | 7.45% | 10.29% |
If you want an explanation of the difference between the Packetised and Memory Mapped benchmarks, please see the Tn homepage (but basically, the Packetised involves performing a lot more memory ops in a more loaded multithreaded environment). As you can see above, the benefits of nedmalloc translate into real world code with more than a 50% speed increase over the default win32 allocator. The Tn speed test is very heavy on the memory bus, so you can expect your own applications to see greater improvements than this.
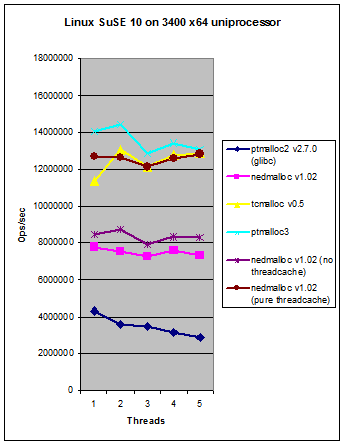
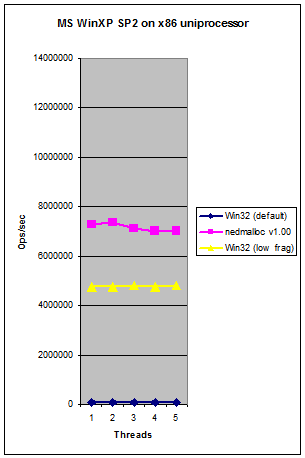
See below for a Frequently Asked Questions list. Below and to the right is a series of comparisons between nedmalloc, system allocators and a number of other replacement memory allocators such as tcmalloc and Hoard. The graphs below are for v1.00 but are still good for an idea of performance on a wide variety of systems, but note than nedmalloc has become much faster in recent revisions (as you can see on the right).
The next generation of memory allocator: the v1.2x series
Since v1.10, and given the outstanding default performance of the Windows 7, Apple Mac OS X 10.6 and FreeBSD 7+ system allocators, nedmalloc has taken a different approach to improve performance: it has begun to implement changes to the 1970s malloc API and kernel VM design whose design increasingly constrains performance on modern systems.
To my knowledge, nedmalloc is among the fastest portable memory allocators available, and it has many features and outstanding configurability useful in themselves. However it cannot consistently beat the excellent system allocators in Windows 7, Apple Mac OS X 10.6+ or FreeBSD 7+ (and neither can any other allocator I know of in real world testing). It isn't any slower than these allocators, but for now we have plateaued with current API and VM design.
For a next generation API design allocator, see the C1X change proposal N1527 at http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1527.pdf). Two reference C implementations of N1527 are also available at http://github.com/ned14/C1X_N1527. This proposed API substantially reduces whole program memory allocation latencies, and the ISO C1X committee have not rejected the idea in principle (they are currently considering whether to make it into a Technical Specification).
v1.10 beta 1 had a first attempt at an improved malloc API. N1527 introduced a second attempt, and resulting from the feedback from the March 2011 ISO C1X committee meeting in London, v1.20 intends to introduce a third attempt at getting the API right. The committee has had an idea of attributed arenas, so basically one creates memory pools which have certain configurable characteristics. This is fairly complex, but solves a whole load of problems present and future at once.
For an example of a next generation VM design allocator (which by the way the new malloc API allows you to use directly through the alignment and size rounding pool attributes i.e. you set both to the page size), you can try the user mode page allocator in nedmalloc v1.10 (Windows Vista or later only). It opens a whole new world of performance and scalability, but requires Administrator privileges to run. Want to know more? Here are two academic papers on the subject:
- Douglas, N, (2011-May), 'User Mode Memory Page Management: An old idea applied anew to the memory wall problem', ArXiv e-prints, vol: 1105.1815.
- Douglas, N, (2011-May), 'User Mode Memory Page Allocation: A Silver Bullet For Memory Allocation?', ArXiv e-prints, vol: 1105.1811.
 |
 |
Downloads:
ChangeLog (from GIT). GIT HEAD (both are identical mirrors):
- git://github.com/ned14/nedmalloc.git (web view)
- git://nedmalloc.git.sourceforge.net/gitroot/nedmalloc/nedmalloc (web view)
Current bleeding edge: v1.10 beta 4 in GIT HEAD.
Current betas: Beta 3 of v1.10 (455Kb). You should use this in preference to any other (it's a very mature beta).
Previous: Beta 2 of v1.06 (svn 1159) (963Kb) Beta 1 of v1.06 (svn 1151) (957Kb) v1.05 (svn 1078) of nedmalloc (80Kb) v1.04 (svn 1040) of nedmalloc (80Kb) v1.03 of nedmalloc (76.4Kb) v1.02 of nedmalloc (76.3Kb) v1.01 of nedmalloc (71.9Kb) v1.00 of nedmalloc (69.7Kb)
Changes last few releases:
v1.10 beta 3 17th July 2012:
- [master 5f26c1a] Due to a bug introduced in sha 7a9dd5c (17th April 2010), nedmalloc has never allocated more than a single mspace when using the system pool. This effectively had disabled concurrency for any allocation > THREADCACHEMAX (8Kb) which no doubt made nedmalloc v1.10 betas 1 and 2 appear no faster than system allocators. My thanks to the eagle eyes of Gavin Lambert for spotting this.
v1.10 beta 2 10th July 2012:
- [master 51ab2a2] scons now tests for C++0x support before turning it on and tries multiple libraries for clock_gettime() rather than assuming it lives in librt. This ought to fix miscompilation on Mac OS X. Thanks to Robert D. Blanchet Jr. for reporting this.
- [master b2c3517] Mac defines malloc_size to be const void *ptr, not void *ptr
- [master 9333e50] Updated to use the new O(1) Cfind(rounds=1) feature in nedtries
- [master 54c7e44] Avoid overflowing allocation size. Thanks to Xi Wang for supplying a patch fixing this.
- [master 5b614a0] Removed __try1 and __finally1 from MinGW support as x64 target no longer supports SEH. Thanks to Geri for reporting this.
- [master 48f1aa9] Tidied up bitrot which had broken compilation due to mismatched #if...#endif.
v1.10 beta 1 19th May 2011:
- [master 89f1806] Moved from SVN to GIT. Bumped version to v1.10 as new ARA contract will involve significant further improvements mainly centering around realloc() performance.
- [master 254fe7c] Added nedmemsize() for API compatibility with other allocators. Added DEFAULTMAXTHREADSINPOOL and set it to FOUR which is a BREAKING CHANGE from previous versions of nedalloc (which set it to 16).
- [nedmalloc_fast_realloc 97d1420] Added win32mremap() implementation.
- [nedmalloc_fast_realloc 8a1001e] Significantly improved test.c with new test options TESTCPLUSPLUS, BLOCKSIZE, TESTTYPE and MAXMEMORY.
- [nedmalloc_fast_realloc 7ea606d] Implemented two variants of direct mremap() on Windows, one using file mappings and the other using over-reservation. The former is used on 32 bit and the latter on 64 bit.
- [nedmalloc_fast_realloc 26ff9a7] Added the malloc2() interface to nedalloc.
- [nedmalloc_fast_realloc 5bc5d97] Rewrote Readme.txt to become Readme.html which makes it much clearer to read.
- [nedmalloc_fast_realloc 2efa595] Added doxygen markup to nedmalloc.h and a first go at a policy driven STL allocator class.
- [nedmalloc_fast_realloc d851bde] Added a CHM documenting the nedalloc API.
- [nedmalloc_fast_realloc dbd3991] Added a fast malloc operations logger which outputs a CSV log on process exit.
- [nedmalloc_fast_realloc d6a8585] Added stack backtracing to the logger.
- [master c7ea06d] Finished user mode page allocator, so merged nedmalloc_fast_realloc branch.
- [master 9a8800f] Fixed small bug which was preventing the windows patcher from correctly finding the proper MSVCRT.
- [master 37c58b1] Fixed leak of mutexes when using pthread or win32 mutexs as locks. Thanks to Gavin Lambert for reporting this.
- [master f67e284] Fixed nedflushlogs() not actually flushing data and/or causing a segfault. Thanks to Roman Tatkin for reporting this.
- [master 1324bf3] Finally got round to retiring the MSVC project files as they were sources of never ending hassle due to being out of sync with the SConstruct config. Rebuilt scons build system to be fully compatible with MSVC instead (long overdue!)
- [master 068494e] As the release of v1.10 RC1 approaches, fixed a long standing problem with the binary patcher where multiple MSVCRT versions in the process weren't handled - everything was sent to one MSVCRT only, and needless to say that sorta worked sometimes and sometimes not. Now when nedmalloc passes a foreign block to the system allocator, it runs a stack backtrace to figure out what MSVCRT in the process it ought to pass it to. It's slow, but fixes a very common segfault on process exit on VS2010.
- [master 4cca52c] Very embarrassingly, nedmalloc has been severely but unpredictably broken on POSIX for over a year now when built with DEBUG defined. This was turning on DEFAULT_GRANULARITY_ALIGNED whose POSIX implementation was causing random segfaults so mysterious that neither gdb nor valgrind could pick them up - in other words, the very worst kind of memory corruption: undetectable, untraceable and undebuggable. I only found them myself due to a recent bug report for TnFOX on POSIX where due to luck, very recent Linux kernels just happened by pure accident to cause this bug to manifest itself as preventing process init right at the very start - so early that no debugger could attach. After over a week of trial & error I narrowed it down to being somewhere in nedmalloc, then having something to do with DEBUG being defined or not, then two hours ago the eureka moment arrived and I quite literally did a jig around the room in joy. Problem is now fixed thank the heavens!!!
- [master 3d55a01] Fixed a problem where the binary patcher was early outing too soon and therefore failing to patch all the binaries properly. It would seem that the Microsoft linker doesn't sort the import table like I had thought it did - I would guess it sorts per DLL location, otherwise is unsorted. Thanks to Roman Tatkin for reporting this bug.
- [master 6c74071] Added override of _GNU_SOURCE for when HAVE_MREMAP is auto-detected. Thanks to Maxim Zakharov for reporting this issue.
- [master dee2d27] Marked off the v2 malloc API as deprecated in preparation for beta release. Updated CHM documentation.
Frequently Asked Questions:
- When should I replace my memory allocator?
If you want your program to run at the maximum possible speed on operating systems before Windows 7, Apple Mac OS X 10.6, FreeBSD 7 or Linux kernel 3.x, you should consider replacing your memory allocator. Fixing up your code to use a new memory allocator is usually easy for most C and C++ projects, but can become tricky if you must maintain compatibility with your system allocator (you must tag each memory block so you can discern between what has been allocated by the system and your custom allocator). If you are running on Windows then nedmalloc can binary patch existing binaries thus avoiding the need to recompile.
- Is nedmalloc faster than all other memory allocators?
No, there are faster ones, especially for specialised circumstances e.g. tcmalloc. However, nedmalloc is an excellent general-purpose allocator and it is based on dlmalloc, one of the most tried & tested memory allocators available as it is the core allocator in Linux. If you use nedmalloc, you will never be far from the best performing specialised allocator. As you might note in the real world benchmarks above, you get severely diminishing returns to allocator improvement once they get into a certain performance range.
- How space-efficient is nedmalloc?
dlmalloc does not fragment the memory space as much as other allocators, but it does have a sixteen or thirty-two byte minimum allocation with an eight or sixteen byte granularity. nedmalloc's thread cache is a simple two power allocator which does cause bloating for items small enough to enter the thread cache (by default, 8Kb or less) but in general, this wastage across the entire program is small. You can configure nedmalloc to use finer grained bins to quarter the average wastage but this comes at a performance cost. When configured to only permit one memory space per thread, memory bloating is considerably less than that of ptmalloc2.
- Is
tcmalloc better or worse than nedmalloc?
As you can see in the graph above, nedmalloc is about equal to tcmalloc for threadcache-only ops and substantially beats it for non-threadcache ops. nedmalloc is also written in C rather than C++ and v0.5 of tcmalloc only works on Unix systems and not win32. tcmalloc achieves its speed by not doing free space coalescing (free space reclamation is one of the slowest parts of any allocator, and is rarely constant time) and simply decommits unused 4Kb pages instead. That means that in a 32 bit process, address space exhaustion is a real concern with tcmalloc, and even in a 64 bit process certain allocation patterns can keep expanding address space consumption indefinitely, all of which requires extra kernel memory to track (i.e. it's a form of slow memory leak). Therefore consider carefully whether tcmalloc is right for your particular application.
- Is Hoard better
or worse than nedmalloc?
As of v1.01, nedmalloc is close enough to Hoard to make little difference in real world code (see real world benchmarks above). nedmalloc's synthetic test seems to trigger a bug in Hoard causing dismal performance, however I trust its author and its design enough to say that Hoard may be slightly faster in certain circumstances eg; if code allocates a large block in one thread and frees it in another. However, Hoard is licensed under the GPL unless you pay which is not the case with nedmalloc.
- Is ptmalloc3
better or worse than nedmalloc?
ptmalloc3 is also a new implementation of ptmalloc2 and is also based on a newer dlmalloc. ptmalloc3 currently outperforms nedmalloc for a low number of threads especially on uniprocessor hardware, but on dual processor and above or with a lot of threads nedmalloc is faster. nedmalloc also runs fine on Windows whereas ptmalloc3 would (to my knowledge) require extra support code.
- Is
jemalloc better or worse than nedmalloc?
Good question! There are many similarities between the designs, and like nedmalloc jemalloc keeps changing its internals over time so whatever I say here is likely out of date! Last time I looked, jemalloc uses red-black trees internally which are considerably slower than binary bitwise trees. On the other hand, jemalloc has the big advantage of a fully integrated threadcache whereas nedmalloc's is literally bolted on on top of dlmalloc and its lack of integration does cost a few percent of performance (but eases my maintenance). jemalloc allocates small blocks more tightly and therefore wastes less memory, but this can introduce cache line sloshing when multiple CPU cores are writing to the same cache line. jemalloc is generally developed on Linux and Mac OS X first and Windows after, whereas I'd target Windows first due to its popularity and the others after. nedmalloc definitely is more experimental with C1X N1527 support (though I'd love if Jason added this too - hint hint!). In short, I'd doubt you'll find ANY performance difference in real world code.