16th December 2004: [TnFOX: 26,825 lines; TCommon: 11,921
lines; TKernel: 4929 lines] It's been a while since the last update but then
I've returned to university which has slowed my code production speed to around
one sixth of what I was achieving when working upon this full time (you can see
this pretty clearly in the graph on the right). On the other hand, I have made
significant progress in the past few weeks - namely that the TransferData and
Kernel.Node.CreateData capabilities are working, both for read and write data.
And they're also pretty fast though currently the biggest thing slowing them
down is string work (really need move constructors in C++ here!). In particular
during the last two weeks I have focused especially on finding and fixing long
standing bugs, so now the entire system cleanly boots and shuts down with no
resources leaked. All the occasional segfaults are gone, as are all remaining
deadlocks. It now feels like production code, which is rather nice!
![]()
After christmas comes the ActAsUser capability, then UI support and a text data structure extractor, possibly with renderer. I'd like to push on with the GUI side of things and am very keen to get going on automatic UI generation as I think that's really exciting and we're finally getting close to being able to realistically do it. However, I also need node linkage working first which will be needed for ActAsUser to replicate namespace entries anyway. It all looks good, it's just a question of free time - and hopefully I can double my code production speed!
23rd June 2004: [TnFOX: 25,846 lines; TCommon: 7828 lines; TKernel: 4148 lines] Capabilities are working (screenshots are of debug build merely with optimisations on so this represents still much lower than maximum. Note that Linux screenshot was running inside VMWare):
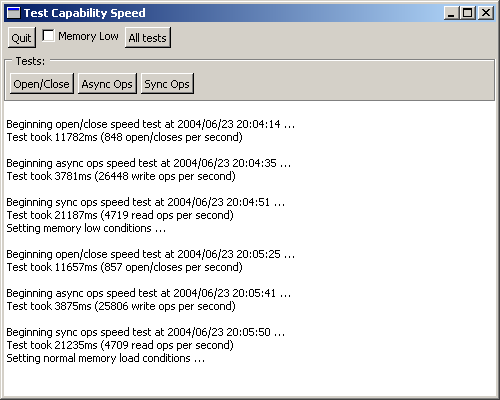
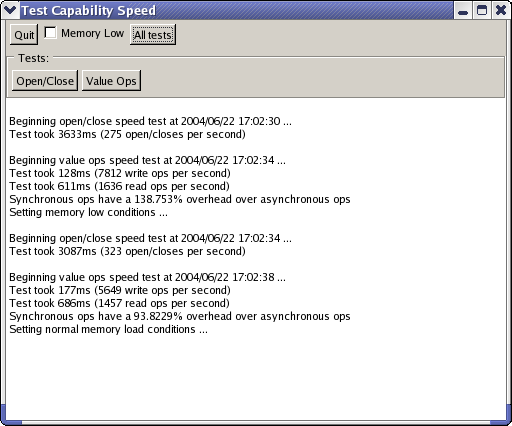
They actually started working Friday the 11th but at only ~50 open/closes per sec and just over 1000 value ops/sec. After some investigation, it turned out that my dynamic hash table dictionary resizer was too primitive - inserting and removing within a std::map is far faster than allocating or destroying a new key entry (with its implicit creation and multiple copy construction of a std::vector). This applies on both the Dinkumware and SGI STL's so I hacked QDICTDYNRESIZE() to be more intelligent when the container is not used for lookups so much or doesn't contain many items.
The other major source of sloth was the infamously awful Win32 memory allocator. I knew it immediately when Linux inside VMWare was pounding the Win32 version into the ground (using the Win32 allocator we get only 95 open/closes per second and 4926 async ops/sec). If any proof was needed of how much benefit an improved allocator can give you, it is the >6x speed gains realised above by simply dropping it in (and I should add that considerable quantities of sanity checking still remain).
I'm pretty happy with the above figures for now. Glowcode tells me that well over half the test time is being spent in the kernel waiting for something and that's good enough for me right now. I tried enabling Whole Program Optimisation in Intel's C++ compiler but it actually went a lot slower - then again the binary from ICC is three times the size of the MSVC binary which translates into not fitting into 256Kb of L2 cache no matter how better quality the code is.
As a comparison, OmniOrb (fastest implementation of CORBA) according to http://nenya.ms.mff.cuni.cz/ can perform ~36,000 asynchronous ops/sec and ~17,000 synchronous ops/sec on a 2.2GHz Pentium IV running RH7.3. That spec is quite a lot higher than mine, but then I also have two real processors as against his two (by hyperthreading) virtual processors. What you see above doesn't actually translate directly - a capability going via the kernel is tunnelled from one kernel connection to another (in this case, the same one) so the asynchronous ops/sec value can be doubled (to ~52,900) and the synchronous ops/sec can be quadrupled (to ~18,800) so thus even with all that sanity checking still in place (never mind tunnelling & connection sharing overheads), we are substantially outperforming OmniOrb in this simple test. I'm pretty sure Tn will be more scalable than OmniOrb too, but I'll enhance the test to use 100 threads later.
Next comes merging latest FOX into TnFOX and release of v0.80. Thereafter comes Tn's natty auto UI generator.
12.58am that night ... Just got a release build working - 1042 open/closes per sec, 29770 async ops per sec (really ~60,000) and 5306 sync ops per sec (really ~21,000). This makes around a 23%/13%/13% improvement when sanity checks are removed.
I also tested the impact of using sockets instead of pipes for kernel/client communication: 675 open/closes per sec, 12981 async ops per sec and 3018 sync ops per sec (making a 35%/56%/43% performance hit).
I also tested the 128 bit AES encrypted secure kernel client connection based on sockets which would be normal for connections to Tn code outside your computer: 456 open/closes per sec, 5633 async ops per sec and 1469 sync ops per sec (making a 32%/57%/51% performance hit, or in terms of against an unencrypted pipe 56%/81%/72%).
27th May 2004: [TnFOX: 24,735 lines; TCommon: 7955 lines; TKernel: 3598 lines] Interestingly, it being around one year exactly since I started this, I've written 36,288 (52,599 including docs) lines of C++ which is reasonably well debugged. I know I can output more than 50k lines of debugged C annually though working substantially less hours. However, as anyone will verify, writing C++ is much harder than C!
The big differences between Tornado III and Tn mainly result from me having rushed the core support so I could reach data streams swiftly. This meant a lot of poor design with the intention of going back and replacing it later though of course this never happens quite as you wish. OTOH, it achieved what I wanted to know which is that the ideas are viable.
Tn, even if accepting that 50% of TnFOX is supplying features Qt had but FOX didn't, already has more code to implement less. This is because Tn does it right all the way through - it's also portable (running on Win32, Linux and FreeBSD - and I regularly test on all three as I proceed), has full strong encryption support throughout, is vastly more robust (is completely exception-safe) and is shockingly faster (to compare - Tornado III was sluggish in debug builds but Tn is very zippy despite reams of extra sanity checking). A number of features have changed - the most major is that Tn is now a full capability based system as against the ACL security of Tornado III but things like my new mastery of C++ metaprogramming have made itself felt throughout the Tn source. Tn also has a fully implemented component infrastructure which was very ramshackle in Tornado III - now even the kernel runs as a component - of course, TnFOX's per-thread event loops have made this far, far easier. I couldn't have done Tn as cleanly as I have on Qt. Tn also adjusts most of its data structures dynamically according to free memory availability which is quite cool to watch and segments remote invoked code into their own memory pool to prevent memory allocation attacks.
Right now I'm in the process of writing a component which tests how fast capabilities can run at. This will be useful to see if future changes speed up or slow down this infrastructure which is at the very core of Tn - everything, absolutely everything is implemented over this infrastructure including data streams. Of course, as I exercise code written ages ago which has never been tested I find new bugs - some in code ported to TnFOX from Tornado III! So it's slow going, but progress is good.
Once I have the capability tester working, I'll post a screenshot. It won't be much - a debug window - but pictures tell a thousand words!