Things became incrementally better with the introduction of XHTML back around 2000 which made HTML compatible with a very wide ecosystem of structured markup - indeed, XML has been one of the great success stories of the past decade in computing. Now don't get me wrong, I think that XML ain't great as a format - it's bulky, overly verbose and too hierarchical to express many types of data cleanly, but I will say that it is almost always better to have something in XML than some proprietary format where everyone has to arse around with writing custom parsers to handle the proprietary format.
Imagine then my great surprise then when HTML5 was announced as a W3C standard. Here they have taken the explicit step of breaking with XML compatibility because "HTML isn't XML". That's rot - HTML which isn't XML is a bug, not a feature. If web browsers added a five second delay and a warning message everytime they saw a non-validating XHTML page then I can assure you that people would either fix their tag soup HTML, or remove the doctype declaring it as a valid XHTML. I don't mind people declaring a page as tag soup, so long as they don't declare it as valid X(HT)ML when it doesn't validate. Otherwise you're breaking an interface contract with your client, and any programmer worth their salt knows that that is a big, big no no!
But to go to the extent of deliberately encouraging people to explicitly write HTML which doesn't validate as XML seems highly retrograde to me. XHTML ought to be the gold standard for all HTML. XML content is reusable and fits into a huge ecosystem. HTML5 needs a custom parser to convert it into XML, and even then a few design decisions made in HTML5 don't map into XML at all well. Setting a different gold standard for HTML which is intentionally incompatible with XML is a braindead, retrograde, and backwards decision in my opinion.
It's not that I don't recognise that in practice you need a custom parser when processing XHTML because very often it's broken in all sorts of ways. It's more that non-XML validating (X)HTML is bad practice and it should be discouraged rather than encouraged.
How to adopt HTML5 semantic features without adopting HTML5
So, I wasn't exactly leaping with joy when I looked at HTML5. It has some cool multimedia features, but nedprod doesn't use any of those. And it standardises a lot of stuff all of which are sensible. But it really doesn't offer much I'm interested in unless I can validate it as XML.
However, then last June schema.org appeared which proposes a HTML5 microdata vocabulary which will be standardised across all the major search engine vendors, thus pushing out alternatives such as microformats and RDF. Because it will almost certainly become the standard, and I am very keen on improving the semantic web, that raised the question of how to integrate HTML5 microdata into XHTML 1.x Strict and get the validating XML parser which checks this website before any changes are uploaded to the internet to not cough all over it.
The obvious solution - at least, until the good folks over at http://www.html5dtd.org/ complete their community developed XHTML5 DTD - is an interim DTD which adds the HTML5 microdata extensions to XHTML 1.0 Transitional and XHTML 1.0 Strict (almost certainly XHTML 1.1 Strict will validate with XHTML 1.0 Strict, they're almost the same specification though the DTD implementations are very different internally). So I went ahead and developed a "XHTML with HTML5 microdata" DTD, and here they are:
- xhtml1-strict-with-html5-microdata.dtd
- xhtml1-transitional-with-html5-microdata.dtd
- Features of both include restoring the target attribute to <a>, adding the <time> tag from HTML5 as well as allowing <meta> and <link> as inline flow elements (necessary for schema.org) and restoring the <iframe> and <applet> tags to HTML 1.0 Strict so embedded YouTube videos etc. don't cause validation fails.
To use, you have two choices. The first is to download the DTD and feed it to your XML validating parser when validating your XHTML as an override to the internally specified XHTML DTD. This works well.
The second and more interesting choice is to replace the DOCTYPE declaration at the top of your XHTML files with one of the following:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict with HTML5 microdata//EN" "xhtml1-strict-with-html5-microdata.dtd">
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional with HTML5 microdata//EN" "xhtml1-transitional-with-html5-microdata.dtd">
You might think that this would trigger Quirks mode in web browsers. Interestingly, IE8, Chrome 14, Firefox 5 and Opera 11.50 all render such a doctype in Standards mode. Yeah, I know who would have thought so? I guess their doctype parser is actually fairly intelligent (or they're keying on the <html xmlns="http://www.w3.org/1999/xhtml"> instead). Who knows!
What can you expect from marking up your HTML with HTML5 microdata? Is it worth doing?
As a test of the new facilities, I marked up the front page on nedprod with HTML5 microdata to see what happens. Here's what Google's microdata testing tool picked up (and you can run this tool on the current front page here):

As you can see, it picks up rather a lot! It realises which section contains the breadcrumbs (the left navigation bar) as well as the fact that there are a number of blog entries, some of which contain reviews and ratings of things. It might not still be Engelbart's 1968 vision, but it's a definite improvement over what we had before.
What does the markup look like? Well:
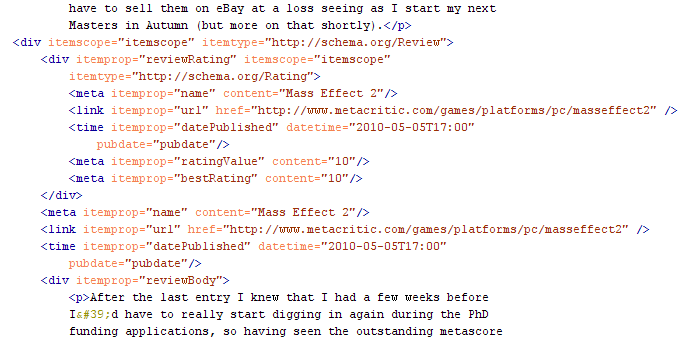
As you can see, I've pretty much ignored the suggestions on schema.org to wrap displayed text with itemprops, choosing instead to silently embed additional metadata in <meta> and <link> tags. This is because the present Google microdata parser can't cope with nested itemprops, so if I try tagging name or url in the reviewBody like would seem obvious, Google's parser skips the reviewBody. Unhelpful, but such is life.
Anyway, the above is straightforward enough. It can be coded up as a snippet in Microsoft Expression Web, so everytime you insert a new diary entry or a new review a template of the above HTML gets added in. I also upgraded my XHTML to Atom RSS PHP script parser to take notice of any <time> tags - this has allowed my virtual diary's Atom feed to contain publication times for the very first time. Nice!
So there we go. HTML5 microdata in XHTML 1.x. And it all fully validates. Hope you find this useful, if so please consider donating to support this site.