What is Tn?
Tn seeks to provide an environment which maximises the evolutionary capacity of your computing system which should result in exponentially rising productivity. If one views tools as augmentations of the mind, and computers as uniquely augmenting both individual and societal (population) consciousness1, then it is obvious that how software is currently structured severely impedes productivity. Software should be seen dually in terms of its structure (substance) augmenting the mind and minds of its users as well as its pattern (form).
That sounds really far out ...
Not really. Software is nothing more than a set of relationships between algorithms ie; organised algorithms (see my notes on this). Humans also have a set of relationships between them and their tools, both at an individual and en mass capacity. Software has relationships with other software via exchanging data - files, the internet etc. One can go on - but basically it's lots & lots of relationships2 and as we know from programming language theory, a lot of the relationships between disparate entities can be inferred and thus generated given sufficient meta-information (ie; software can organise itself to a certain degree3).
Wherever you get a lot of dynamic intertwined relationships with feedback loops, you get complexity theory and ecosystemic behaviour4. Therefore surely one should design software with a view to maximising the benefits and minimising the bad points? Well unfortunately historically computer science has not had much interest in biology and where it did in AI it was mostly in a reductionist sense which is of no use. Indeed even now the thought of introducing ecosystemic principles into software design is well into the blue sky of academic research and I know of no one else working in this direction5
Where did you get these ideas from?
I actually had them in 1995-1996 when I was far below the experience & capability required to implement them - I didn't even have the terminology to describe them (and unfortunately, as many will have noticed above the terminology is still not widely familiar). While the ideas clearly have metamorphised over the years (in lieu of experience mostly), one can still clearly see elements in screenshots of the 1996 work though data streams and are probably the best surviving original feature.
But where exactly did they come from? I don't really know. I wasn't familiar with any research, nor much of any systems outside Acorn RISC-OS. But I do know Acorn RISC-OS played a pivotal role in how they formed. Old Acorn RISC-OS programmers & users will find much familiar in the style of Tn. Ultimately though they came from where all creative steps come from, entropy, and I just happened (luckily?) to be its conduit.
What about "Tornado I", "Tornado II" etc?
I made two attempts with Tornado II petering out in 1998 and it wasn't until two years ago (April 2002) that I had another opportunity to investigate them. Thankfully I had nearly a year to write Tornado III unmolested and the success of that convinced me that the ideas were eminently practical.
In the meantime, I was reading a wide range of books on quantum mechanics, biology & economics which finally supplied me with the formalised terminology and metaphors to draw from. Despite failing to seek venture support to turn these ideas into a company (the tech crash didn't help), I decided in May 2003 that Tornado III needed to be moved to use a portability library other than Qt so that I could have much more control over it. This caused me to start TnFOX whose major features I finished in February 2004.
By this stage it was painfully clear that much of Tornado III would need to be rewritten anyway (despite the Qt API emulations), so I started again from scratch. The benefits of having a portability library I could extend and tweak on demand became immediately obvious and great progress has been made.
When will it be released?
Who knows? I am also undertaking another bachelor's degree (this time in Economics, Management & Philosophy) and last academic year it reduced my productivity to 1/6th of working on the code full time - nevertheless, during that time I still wrote & debugged over 3000 lines of code into a project now nearly 50,000 lines in length. There certainly is a good few more years left yet, and as a practically usable system it will be some time thereafter again. Unlike previous efforts, Tn is the most advanced of any previous incarnations and it doesn't carry any poor design choices so in theory, when enough of the foundations have been laid, progress should just snowball at some point.
I originally had the intention of gaining some investment capital and forming a business from it, but it proved impossible as it's too radical for investors. As I'm now on a considerably different career track, I'm no longer sure what I'm going to do with it - but be assured, when I feel it's ready it shall be released somehow, probably with some of its source (most likely all of the client library)
View a Presentation on Tn (slightly out of date)
|
[1]: This is not an orthodox understanding of intelligence ie; that populations of people have a distributed consciousness which can be quite independent from its individual members - however it is correct and it's what makes one culture different to another. On a scientific level, there is ample evidence which shows that all complex biological networks exhibit multiple layers of cognition - indeed, the organisation of neurons in our brains is isomorphic to an ant colony so why shouldn't a million interconnecting humans exhibit the same? See the Ant Fugue in Gödel Escher Bach by Douglas R. Hofstadter (an excellent book though containing mistakes - understandable given its age).
[2]: Consult Zen and the Art of Motorcycle Maintenance by Robert M. Piersig for an excellent description of the existential relationships between the engineer, his/her tools and the thing they are working upon. Ignore the crap about quality & Zen.
[3]: A good example is any functional language where you tell the computer what to do instead of how to do it. This creates what I call a magnifying effect whereby one action of the human gets multiplied severalfold - this is why modern man can achieve far more in one day than man in bygone eras - the magnifying effect of modern tools is that much greater (after all, biology limits maximum human output!). What this isn't saying is that the computer becomes intelligent - it still can't originate actions on its own, just automate a lot of what you have to do yourself manually right now.
[4]: The best book I know on this is The Web of Life by Fritjof Capra which thankfully comes with an extensive bibliography. Among the books it summarises that is particularly useful is The Tree of Knowledge - The Biological Roots of Human Understanding by Maturana & Varela.
[5]: Inferno (née
Plan 9) now marketed
by Vita Nuova but originally from
AT&T labs under the stewardship of
Dennis Richie (of
Kerningham & Richie fame) comes the closest to Tn. Plan 9 was a ground-up
extension of where Unix should go next. I didn't find out about Plan 9 until
2002 when Marshall
Cline told me but at least it signifies I'm going the right way.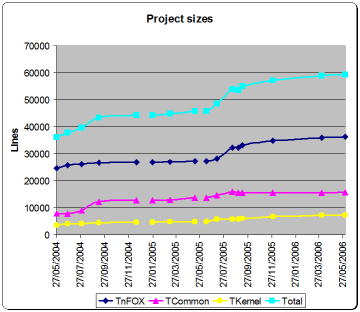 Update: There is now actually some research into along these lines in
AI research (they are called psynets), about which
you can read more here.
Update: There is now actually some research into along these lines in
AI research (they are called psynets), about which
you can read more here.
Project Diary:
1st June 2006: [TnFOX: 36,403; TCommon: 15,718; TKernel: 7,288] As you can see, the line count has barely changed. However, here's something new and nice:
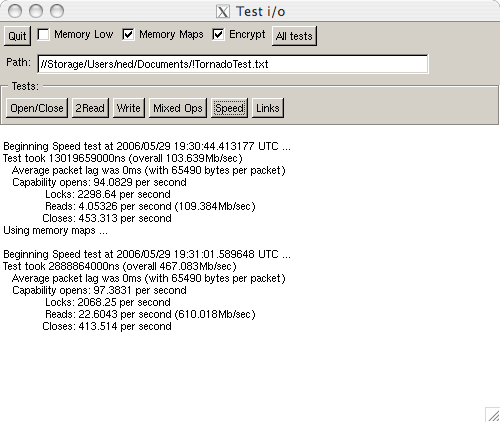
Yup, Tn is now running on Apple Mac OS X! This is before speed tuning, but already it's posting a fairly nice result - it's about half the speed of Linux, but still way faster than Linux was before the last update. You can sadly see the lack of Xft font support in Apple's X11 implementation - it's supposed to work, but if I enable it I get segfaults, so we're left with the old xld fonts which just look nasty.
I still have a week or so to go before I head home and can start coding proper, so don't expect a lot of code to get written. I'm likely to do some tidy-ups eg; the python bindings first before gutting the i/o locking system in favour of a data structure extractor locking system. Amazing to think all that work I put in last summer just hasn't been put to use all this academic year - the workload has simply been immense. I'm sure I'll post another update within a month. Good luck!
15th April 2006: [TnFOX: 35,931; TCommon: 15,701; TKernel: 7,282] Not much has changed apart from some further optimisations and bug fixes, most significant of which are on Linux. Most of this optimisation comes again from within TnFOX as I made the v0.86 release during the Easter break - between that release and nedmalloc, all my coding time has been occupied. This release adds FOX v1.6, but Tn is still based on the v1.4 branch and should remain so for the time being.
Optimisations include an ever improving nedmalloc, which is now the fastest allocator on any platform to my knowledge. I also finally managed to profile the Linux build using kcachegrind and oprofile, having previously been unsuccessful to date with gprof (it had issues with threads). It turns out that pthread_getspecific() which gets called a lot in my code is not a fast call and that a previous optimisation of using sockets instead of pipes on Linux (as they used to be faster on 2.4 kernels) is no longer the case. Also, the code for FXProcess::mappedFiles() was seriously slow on Linux due to use of single character i/o and sscanf(), so I cached that and minimised the use of the unavoidable pthread_getspecific(). The results are as follows:
| Memory Mapped (Mb/sec) | Packetised (Mb/sec) | |||||
| Previous | New | % change | Previous | New | % change | |
| x64 on Win64 (msvc8): | 838.2 | 839.2 | +0.1% | 166.1 | 204.1 | +22.9% |
| x64 on Linux (gcc4.1): | 192 | 437.5 | +127.9% | 25.8 | 202.9 | +686.4% |
This brings Linux performance in line with Windows performance for the first time ever! Needless to say, I am delighted! Windows still has nearly twice as fast memory mapped i/o than Linux, and of course GCC 4.1 is performing full aliasing optimisation which means it's still really about 8-10% slower than MSVC. But what a world of difference!
As you can see by the 22.9% improvement in x64 on Win64 results, I also got to the bottom of poor performance on msvc8 with the help of Microsoft. It turned out that std::vector construction is much slower on msvc8, and furthermore many extra sanity checks are enabled by default on msvc8 in release builds. Disabling these and replacing std::vector with a good old calloc() implementation got the results to within 8% of msvc7.1 with the remainder being lack of aliasing optimisation on msvc8. If you disable aliasing optimisation on msvc7.1, you get identical results. Microsoft don't seem to want to restore aliasing optimisation, so I guess this is a permanent performance loss on x64.
What comes next? A little more testing of link nodes, and I'll be ready to replace the i/o locking infrastructure with a pure data structure extractor implementation. This will probably happen this summer - but I also want to make a try on a new Economic model this summer, so time will be more limited. Needless to say the new Economic model will use TnFOX and I'll almost certainly throw it away afterwards with the intention of building a superior model on Tn itself the following summer. At the very minimum, TnFOX will gain new graphing abilities which can generically interface with any underlying data source eg; a SQL database, or a Tn data structure extractor.
30th November 2005 (updated 19th December 2005): [TnFOX: 34,868; TCommon: 15,656; TKernel: 6,683] It turned out that link nodes took an awful lot longer than I had hoped, but not because it was hard per se, but rather that this university course has been extremely demanding of my time. I probably haven't put in more than five days on Tn itself since the start of term, though I have spent additional coding time fixing bugs in TnFOX, writing an improved memory allocator called nedmalloc (yet to be released) and helping Roman Yakovenko author of pyplusplus to develop a new set of python bindings for TnFOX.
And I should add that link nodes aren't entirely tested yet. Tn is correctly parsing links (both shell and symbolic) on both Windows and POSIX and it seems okay generating a link too. But I won't pretend that it's fully tested yet. In reality, that'll probably have to wait for Christmas.
I spent much of today nailing a particularly bad bug in the TransferData capability which was preventing the speed test from working. Turned out to be that I had left out a break instruction and code which should never have been run was corrupting memory. This major oversight of mine came from the changes I made by splitting TransferData into two: TransferRawData and TransferData with the difference being that the latter can decrypt encrypted data. So now I can finally post some new benchmarks which are far more representative as all the security & encryption code is now in place and running. The previous figures are from the 14th May 2005 entry below and are for the overall speed (sustained transfer rates are higher).
| Memory Mapped (Mb/sec) | Packetised (Mb/sec) | |||||
| Previous | New | % change | Previous | New | % change | |
| x86 on Win32 (msvc7.1): | 512.2 | 711.5 | +38.91% | 147.9 | 164.3 | +11.09% |
| x86 on Win64 (msvc7.1): | 570.3 | 800.6 | +40.38% | 180.5 | 227.4 | +25.98% |
| x86 on Win64 (msvc8): | - | 779.5 | -2.64% | - | 161.4 | -29.02% |
| x64 on Win64 (msvc8): | 608.6 | 838.2 | +37.73% | 165.4 | 166.1 | +0.42% |
| x64 on Linux (gcc4.0): | 56.2 | 192 | +241.64% | 37.5 | 25.8 | -31.2% |
| x64 on FreeBSD (gcc4.0): | 56.2 | 37.5 | ||||
The % change (in italics) for x86 on Win64 (msvc8) is the change from the same with msvc7.1. Yes, it is substantially slower.
On Windows msvc8 produces substantially slower code than msvc7.1 despite their claims that their "blended architecture" optimisation model is superior. Me personally, I choose anytime telling the compiler what instruction set to use rather than it trying to be a jack-of-all-trades which surely has to be slower. Also, I must admit to being disappointed with the effective performance decrease of the RTM msvc8 versus the Platform SDK version - one would have expected a 11 to 25% increase due to the overall performance improvements but the fact we're not seeing them suggests that Microsoft have recently done something bad to their compiler. I would suggest that whatever is making the -29% loss for x86 msvc8 is probably doing the same to the x64. [Note that this problem has been reported to Microsoft]
Regarding the Linux and FreeBSD figures, there has been a compiler change from v4.0.0 to v4.0.2 though that effect should be minimal. Far more important is the change from Linux SUSE 9.2 to 10.0 and FreeBSD 5.4 to 6.0 and you can see that Linux has both improved and damaged the figures. FreeBSD 6.0 simply could not run past auto-opening the primary entity for the test component - I think that libc on 6.0 is thread broken and gdb just won't last long enough for me to find out why (gdb on x64 has infinite stack backtracing issues).
One should note that the most amazing thing is that most of those speed increases are from performance optimisations in TnFOX, not Tn which has actually become considerably more bloated!
13th September 2005: [TnFOX: 33,333; TCommon: 15,611; TKernel: 6,061] Well tis the end of the summer! I return to Scotland tomorrow morning, and thankfully I have the project more or less wrapped up for now. I've done well, having written 9,196 lines of new code - more than 20% new code - at a rate of no less than 99.96 written & debugged per day (including holidays when I didn't work), which beats my previous all-time highest productivity of 66.48 written & debugged per day last summer. That's a whole 50% higher productivity!
I didn't get as much done as I had hoped, but that's always the way. TnAdmin can now export key rings to the user's home directory so TShell can pick them up and attempt an ActAsEntity open rather than using the kernel's own list of keyrings. If you plaintext encrypt the keyring, TShell can now ask for a password securely on both Windows and POSIX. I fixed a long standing problem in the kernel //Storage change monitoring updates whereby changes the Tn kernel made to the host OS filing system were corrupting the internal state due to creation times not being supported on a number of filing systems. I fixed some problems in generating multiple versions of data, and lastly I made a start on kernel namespace links for which a large amount of support code was needed in TnFOX - to parse NTFS junction points and Windows Shell links. The latter even works on windows partitions mounted on POSIX as I reverse engineered the Windows Shell .lnk file format. All that new code is now in TnFOX's SVN repository.
Kernel namespace links required updating the kernel node structure so each version could have its own list of subnodes - hence //Home;2 can point somewhere totally different to //Home;5 though I also needed that for data structure expansion into the kernel namespace eg; if you have a ZIP file, the Tn kernel can expand its structure into subnodes such that the directory hierarchy inside the ZIP file appears, thus making the ZIP file appear like nothing other than a special form of directory. Similarly, HTML or Word files could be similarly expanded so everything's basically a directory. On the subject of data structure extractors, I had had a problem in that the generic data locking class (called TIOLock) would work with a TransferData capability or a DataServerBase, but how do you make flat data spaces work with a Query capability returning a database over an IPC connection? The answer is obvious - remove TIOLock completely, integrating locking into the data structure extractor for that type so a Data=>Grid DSE would know if it's working via a local database (in which case lock regions of a flat data space, which would implemented by locking via a SQL cursor) or a remote database, in which case FXSQLDB_ipc does the remote locking for you. Of course, TDSEBase, the base class of a data structure extractor, will contain much of the machinery TIOLock now provides as most of the DSE's will work with nothing other than flat data spaces.
And that's where it stands - Tn has never run so stably or as fast and more bugs are fixed than ever. The backend of Tn is complete except for link nodes. Link nodes won't take long, and a few more weeks will have DSE's for data and grid types implemented (which is the start of Tn's middle end). One simply needs to add the ability to SQL query kernel nodes and one has implemented the guts of TFiler which shall be the first data renderer written for Tn. In the process of fully implementing TFiler, we shall need to implement TWindow (the base class for a top level interface in Tn) with its unique window furniture and TMenu the data renderer of the self-generating Data=>UI data type. Most of the UI shall be database driven, and because of DSE's Tn automatically handles things like current user item selection (ie; highlighting items with the mouse) and generating the correct menu entries for that selection. You simply fill in the slots of functionality, and Tn does everything else - you specify what to do, not how to do it. As you might imagine, writing components for Tn will be orders of magnitude quicker & easier than any current Rapid Application Development tool.
2nd September 2005: [TnFOX: 32,297; TCommon: 15,566; TKernel: 5,792] The graph on the right shows a dip because I was in the process of gutting out some code when I took my two week holiday - and as it turns out, I was nearly finished as it's only taken a full day of work to finish replacing that code. So basically the last two points are before my holidays and just after ie; today.
Basically I have done what I said I was going to do last entry - implemented the guts of what will be Data=>Grid via the new SQL Database support just recently added to TnFOX - the most important part of which was FXSQLDB_ipc as basically that'll be the workhorse of the new Query capability which will form the core of rendering kernel namespace entries into a GUI. Of course, FXSQLDB_sqlite3 is also somewhat important as it'll be used as the main SQL engine in Tn.
However before the data structure extractor for Data=>Grid could be written, as I mentioned last entry a type registry was sorely needed in order to remove the compile-time constraints I was running into with tagged data. This has been done, and it at last enables a 100% polymorphic container which can furthermore render its contents into a GUI:
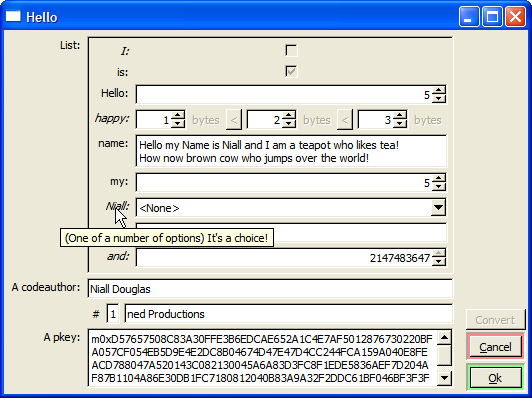
Now that is in fact the oldest test in the Tn TestSuite - and it has been untouched since February 2004. However despite me completely gutting the internals of TTaggedData and TTaggedDataBox and almost completely reimplementing both, the API semantics remain unchanged and all code just goes on working. One major difference is that TTaggedDataBox used to have how to render each supported type hardwired into it, but what you see above is rendition via the type registry. This looks clunky for the time being, but each renderer can actually render in more than one way and supports a limited form of options. You should note that the "List" entry is actually another TTaggedDataBox reflecting the nested TTaggedData inside the main one - obviously, you can nest this stuff just fine.
The type registry is one of those things C++ should have built into it - it's annoying having to write up the usually very small bits of wrapper code to indicate "This can serialise", "This can convert into X" etc. On the other hand, it's far less painful than it could be - I wrote up some policy-based metaprogramming that leverages what the C++ compiler knows at the point of declaration to the type registry to mostly automatically perform everything for you. One can of course override eg; when a type normally moves instead of copies, one must point the registry at the copy method for things to work correctly. However, it's strange to have to do things manually in C++ which is inbuilt in Objective C or Python.
Now I have about a week of coding time left before I must return to St. Andrews, so it leaves me in a dilemma about what to do next. I could just get stuck into the new Query capability which would require implementing the Data=>Grid data structure extractor really as it can use a Query capability as transport, thus pushing towards clients being able to query the kernel namespace. But that would take longer than a week for sure, and I may not want to rush into that when I can't be sure I'll finish it. So what I'll probably do is implement kernel link nodes and the ability to mark up attribute access methods in class types so a set of objects can be dumped into a SQL database (I'm thinking that in the kernel, you simply feed the relevant nodes to some generic code which dumps them automagically into a SQL DB via the type registry).
And then, one really is ready to push forwards with the UIs!
14th July 2005: [TnFOX: 28,232; TCommon: 14,688; TKernel: 5,750] One month in and a lot of new code written now that I am back to full time development. I have also shown breaks from coding in the graph to the right which were for exams or holidays etc.
Lots of small things have been implemented, including the ActAsEntity capability which now works perfectly, user & application preferences and data metadata. TShell opens ActAsEntity's for each component based on the host OS user running TShell. Many things have been finished, including creating of new data (though still lacking a full set of data structure creators), accessMe checking plus correct assignment of accessMe's and accessOthers' for the ReadData, WriteData and CreateData capabilities based on host OS permissions and lastly auto-decryption and encryption of data in the client-side TransferData implementation (though this still needs to be debugged as I ran out of time before Johanna arrived). Immediately next comes link nodes with per-entity namespaces via overlaying the namespace with a series of links.
And with that, I shall have rounded off most of the core functionality required in Tn. I have been thinking more about Data=>Grid - it makes sense to unify its implementation with that of TTaggedData which has the type of Data=>Grid=>Tagged Data as the existing implementation relies on dynamic indirection of type lists to implement its polymorphic container - but this is limited to sixteen types, and I'll be needing a lot more than that. Therefore, some sort of type registry where one can associate serialisation & deserialisation routines for each type, type convertability and type to GUI interface renderers would be ideal especially as then, one can auto-convert a class instance to a database row and back again based mostly on compile-time type introspection. This then allows one to query any running component via database query which sounds most useful indeed, especially as one can optimise local-computer database results transfers by simply opening the database and issuing the same query rather than passing all the results down TConnection. Obviously, as TKernel is just another component, this makes querying the namespace a trivial matter to implement and it also fixes a previous concern I had about implementing TFiler in the most reusable way possible. The most challenging part of this implementation is going to be implementing the user interface rendering in that the user can interact with the render - much like you can operate Explorer on Windows from within any Open File dialog - though bearing in mind that nested renders all must cooperate with one another. It's also going to be a real test of efficiency of implementation - if you think about it, this is a mini-form of data streams in that renders can involve indirecting through multiple independent portions of code, some of which don't run in the local process (or even computer). Of course, given this, it is highly likely I shall make the data stream implementation heavily dependent on this new type registry.
Oh lastly - I may not use FastDB after all, but perhaps SQLite instead. It has a more complete implementation of SQL, and I'm also tempted to have the option of maintaining a lazily-maintained cache of the host OS filing system so one could query everything in the namespace (that being the local and all computers) using one single capability somewhat like Apple MacOS X. Using SQLite would make this much easier than FastDB I think as you can create database views. Also, I'd like the ability to mount such views into the namespace, so parts of the namespace would merely represent queries on the namespace - indeed, I plan to implement UI's (User Interface's ie; menus) directly as database views.
15th June 2005: I haven't bothered with a line count as I've done so little given I've only been working on Tn since Monday (and today is Wednesday). I have however been working mostly on my AdminTn tool which is used to create and manage the Tn home directory seeing as the kernel can't do this yet. Most especially I have been testing the new key ring feature on which entities (users) hold their decryption keys so that I can get to work on the ActAsEntity (formerly ActAsUser) capability. After I have this working properly, I'll get on with full entity support in Tn, including maintainance of //Entities in the kernel namespace (for which I shall need node linking so the per-entity dependent node entries such as //Home can map to //Entities/<entity>/Home. Here's what it looks like:
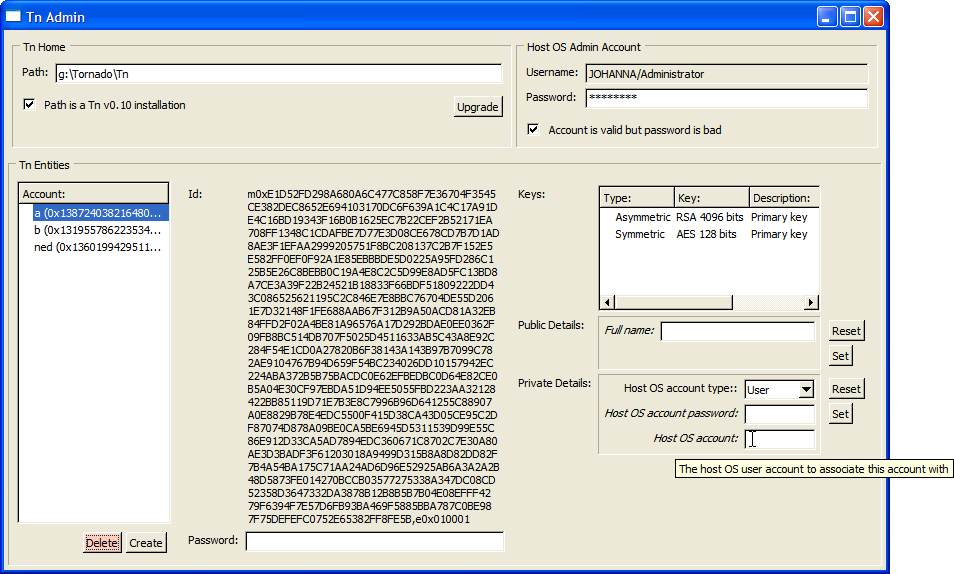
As you can see, the user id is rather long! Each entity is uniquely identified on the planet with one of these and it's also the public part of the entity's primary public/private encryption key. To log on, the kernel encrypts some random data using the entity's public key and sends it to the client side, which decrypts the data, hashes it and sends back the hash. If they match the entity gains the capability to act as that entity. Therefore you can export some or all of a user's keyring to removable media such as a floppy disc where you can password encrypts with some plaintext - this is just cursory protection, as it is the keyring itself which lets you authenticate with a kernel.
Planned for this summer is getting entities working, along with auto-decryption of encrypted data (which the TransferData capability already supports, though it's untested). This will include per-entity namespace entries and node linking as aforementioned, and I'd also like to get the data structure system fully working with an implementation of Data=>Grid with Data=>Grid=>Namespaces as its first real-world use. Data=>Grid=>Namespaces is obviously the results of a query of the kernel namespace and like all Data=>Grid subtypes shall be interrogable using SQL (for which I am planning to use FastDB). If there is time, I'd like to write a data renderer for Data=>Grid=>Namespaces as the first stages of TFiler, the Tn kernel namespace browser.
14th May 2005: [TnFOX: 27,344; TCommon: 13,680; TKernel: 4,785] I simply haven't had the time since the last entry to put any work into Tn - uni has been crazy, as was my supposed Easter holidays. I have however finally got my new 64 bit capable laptop and well it's fast, around three times faster with TestIO than my dual Athlon 1700. Much of the cause of that is the much improved memory bandwidth in newer machines - 400Mhz versus 266Mhz - especially as TestIO is very heavy on the memory bus with two parallel processors.
I also for the very first time have some native figures for Linux and FreeBSD, as well as figures for Win64. As you will see, the Win32 version still pounds them all into the ground - which was unexpected, especially for the Win64 build but I'll talk about that shortly. I have a new Linux - SuSE 9.2 for amd64 and a new FreeBSD v5.4, also for amd64 - and as you will shortly see, performance has improved on FreeBSD immensely now they have disabled many of the threading debugging options in v5.4. Lastly, the compilers used were MSVC7.1 as usual for Win32, MSVC8 from the AMD64 SDK (which is over a year old) and GCC 4.0 for Linux and FreeBSD (which generates slightly slower code than 3.4 due to the new optimiser). The hardware is a Clevo D400J laptop with 1Gb RAM, 3400 Athlon64 Mobile and a VIA K8N800 chipset. All tests were performed with "Cool n' Quiet" disabled to get accurate results.
| MS Windows XP - Win32 Native | MS Windows XP x64 - Win32 on Win64 | MS Windows XP x64 - Win64 Native |
|---|---|---|
 |
 |
 |
| FreeBSD 5.4 - x64 Native | SuSE Linux 9.2 x64 - i686 on x64 | SuSE Linux 9.2 x64 - x64 Native |
 |
 |
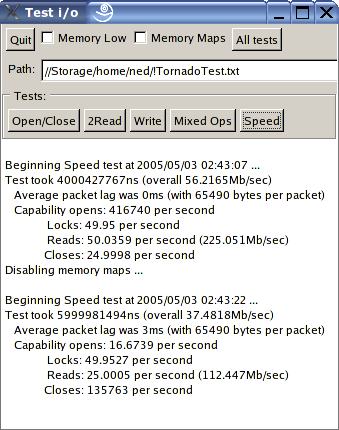 |
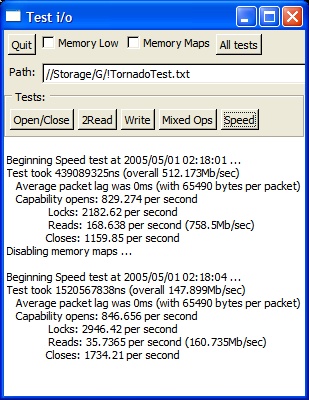
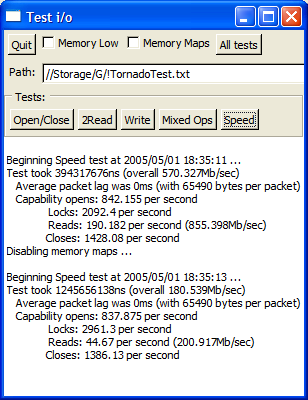
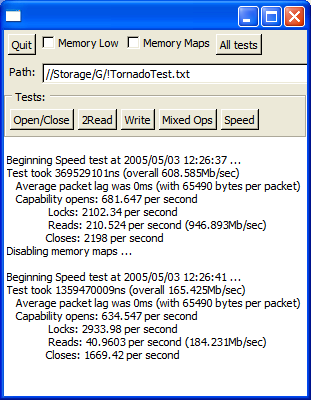
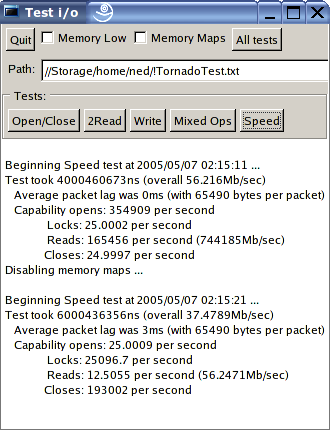
Now there are some surprises above! Bear in mind that the microsecond timer on Linux and FreeBSD stutters a little when under load, so for the POSIX screenshots please compare the overall scores NOT the individual ones. Here are some observations:
- The Win64 version has superior memory mapped i/o to the Win32 - probably because x64 assembler can shuffle twice as much data in the same ops.
- The Win32 version runs faster on Win64 under emulation than the Win32 running native.
- The Win64 version is slower for packet based transfers than the Win32 version - but only when running under emulated Win32, otherwise it's quicker (than the native Win32). I'm not sure why this might be, other than a poor (old) optimiser for x64.
- On Linux it makes no speed difference whether you run 32 bit or 64 bit native binaries. This makes sense, though you would have thought that GCC could make good use of the extra registers to improve performance!
- Memory mapped i/o performance really sucks on Linux - it's not that much faster than buffered. I had said so before as the figures in VMWare were just so far out, but what's surprising is that my vastly faster laptop only achieves a 2x speed increase over the same in VMWare on the dual 1700. Interestingly, synthetic benchmarks place this laptop at exactly 2x the speed of my desktop (uniprocessor).
- On first sight, you might think there is something funny going on in FreeBSD as it posts precisely the same scores as Linux. However, on closer examination, it turns out to be simply a remarkable coincidence - if you adjust any of the parameters, the figures get worse. However, that said, it is clear that FreeBSD still needs some optimising because the memory mapped i/o test noticeably hangs for long periods of time (no doubt due to some sort of priority inversion) - if it ran at its full speed, it would beat Linux by at least three to five times. I did try recompiling the kernel with SCHED_ULE but it made no difference to the scores. Whatever the case, FreeBSD 5.4 is now at least as fast as Linux for the first time ever, and has plenty of scope to go a lot faster.
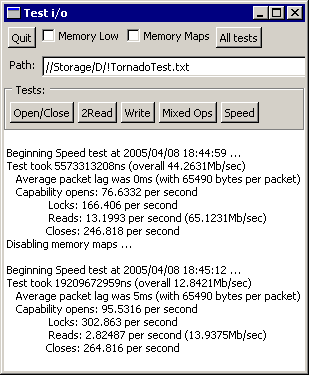
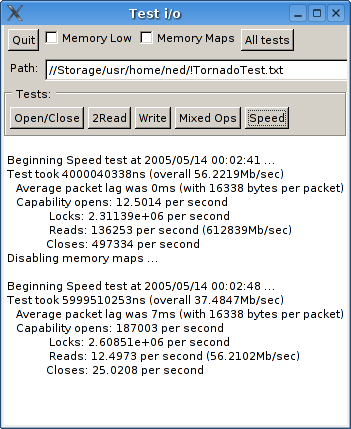
Also just for the laugh when at home for Easter break I ran the speed test on my old 400Mhz AMD K6-3 which gives the screenshot on the right. It's still fairly respectable for the memory mapped i/o - probably because it has 100Mhz SDRAM in it - but shows its age for the packet based transfers. To put the Linux & FreeBSD scores into perspective, they are only 1.25 to 2.9 times faster on a 2.2Ghz Athlon64 than on a 400Mhz K6-3 running Windows. This is not what I call impressive!
Well obviously enough with exams on at the minute there will be no more development work done until the Summer break. What I have done is got this laptop up to fully working for all systems so in theory there should be nothing stopping me from getting on with things during the summer and really getting some work done. So despite the frustration of not adding anything really new since before Easter, I do have 64 bit clean code fully compiling and working on all platforms - which is good enough.
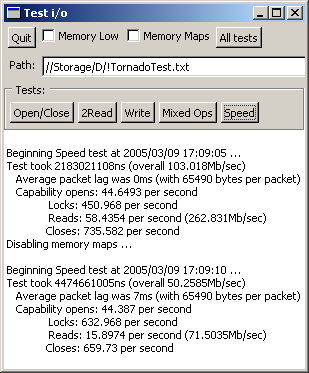
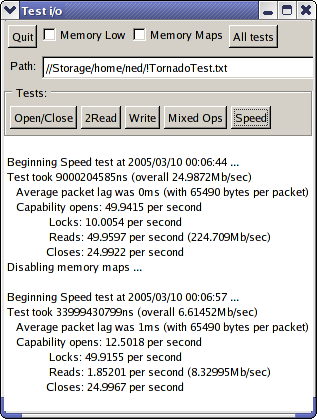
10th March 2005: [TnFOX: 27,044 lines; TCommon: 12,044 lines; TKernel: 4949 lines] I've not had as much time as I would have preferred to work on this since the last entry due to exams and a new girlfriend and such, but the work that I have done has improved quality quite a lot - if not functionality per se. It certainly has taken a while to get all the kinks out of the TransferData capability, and then I had to go optimise it as well but I think the results speak for themselves. Some interesting realisations about performance were made eg; that FAM on Fedora Core 3 is totally broken and was killing performance by stalling for a half second per capability open or so. On FreeBSD, Tn is now at least running at a useable speed once I realised that the system memory allocator doesn't like getting used heavily by too many threads at once so I had it replaced with TnFOX's ptmalloc2 based implementation - though this said, Tn on FreeBSD still remains much less stable than on Linux. But enough with the blather, let's look at the screenshots:
| MS Windows 2000 | Fedora Core 3 (inside VMWare) | FreeBSD v5.3 (inside VMWare) |
|---|---|---|
 |
 |
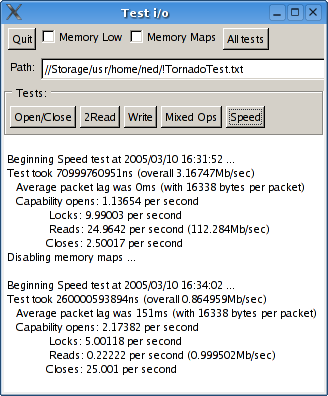 |
Figures are for a 4.49Mb test file and using up to 64Kb buffer pipes or
sockets as the kernel transport (TransferData knows how to optimise how big
the packets it should transfer, so the figure above is 64Kb less headers) -
here you can see good use of the new high resolution timer facilities in
TnFOX.
![]() You
can see that FreeBSD uses 16Kb pipes as they are that size on FreeBSD - on
Linux pipes are 4Kb, so it's actually faster to use a socket. Furthermore,
you can see that FreeBSD v5.3 still has a lot of efficiency issues with
threading - it's less than half the speed of the Linux version even when
using memory maps where it's faster than Linux. However, overall, what is
most clear is that file i/o is pretty damn good - nearly that of raw memory
maps when memory maps are available (around 290Mb/sec on my machine), around
71Mb/sec when packetised over a pipe-based TConnection which is well faster
than hard drive speeds currently (and of course, as they improve so do CPU
speeds so it'll always be higher). As you can see from the graph on the
right, packet-based transfers scale nicely with transfer rate with 4Kb
packets just beating half the transfer rate of 64Kb packets - and
furthermore, packetised transfers will fully utilise both CPU's on a
multiprocessor machine increasing throughput by about 50% (it's not higher
probably because of cache pollution).
You
can see that FreeBSD uses 16Kb pipes as they are that size on FreeBSD - on
Linux pipes are 4Kb, so it's actually faster to use a socket. Furthermore,
you can see that FreeBSD v5.3 still has a lot of efficiency issues with
threading - it's less than half the speed of the Linux version even when
using memory maps where it's faster than Linux. However, overall, what is
most clear is that file i/o is pretty damn good - nearly that of raw memory
maps when memory maps are available (around 290Mb/sec on my machine), around
71Mb/sec when packetised over a pipe-based TConnection which is well faster
than hard drive speeds currently (and of course, as they improve so do CPU
speeds so it'll always be higher). As you can see from the graph on the
right, packet-based transfers scale nicely with transfer rate with 4Kb
packets just beating half the transfer rate of 64Kb packets - and
furthermore, packetised transfers will fully utilise both CPU's on a
multiprocessor machine increasing throughput by about 50% (it's not higher
probably because of cache pollution).
I can't say though that I'm particularly happy with the implementation of TransferData - it's already the second rewrite of that code (the first try coming free with TnFOX as a demo). I think it can still go faster again, plus the code is a little creaky and overly-complex for what it needs to do so a third rewrite is on the cards. However, as I still don't know what's wrong with the current implementation, I'm going to keep it for the time being - with the view to rewriting it later when I know precisely what any new version would need to do.
What comes next? I've ordered a new laptop which is 64 bit capable so the immediate future holds testing TnFOX and Tn as 64 bit builds and noting the likely amazing speedups. Thereafter, almost definitely the ActAsUser capability as without user support finished, there isn't really anything else I can do. After that would come the per-user namespace stuff which would require link node implementation - link nodes being like a super-duper form of symbolic links on POSIX. And after that, well, I guess I start the UI code!